فایلهای خروجی
بهطور کلی، نوشتن روی دیسک حتی در مدرنترین رایانهها با SSD نیز کند است. سرعت جستوجوی دیسکهای مکانیکی در طول تاریخ آنها تغییر کمی کرده است. بنابراین اغلب نوشتن دادههای خروجی روی دیسک سخت، زمانبرترین بخش هر شبیهسازی است. بهصورت پیشفرض OghmaNano همه فایلهای خروجی را روی دیسک مینویسد؛ این کار برای آن است که کاربر جدید بتواند درکی از خروجیهایی که OghmaNano میتواند ارائه دهد به دست آورد. با این حال برای سریعتر کردن شبیهسازیها باید مقدار دادهای را که روی دیسک نوشته میشود محدود کنید. پنجرههای ویرایشگر شبیهسازی (حالت پایا، حوزه زمان و غیره) گزینههایی برای تعیین اینکه چه مقدار داده را میخواهید روی دیسک dump کنید ارائه میدهند. این موضوع در شکل 19.1 نشان داده شده است.
 [H]
[H]
گزینه «جزئیات خروجی روی دیسک» را میتوان بین «هیچ» و «همهچیز را روی دیسک بنویس» تغییر داد. وقتی «هیچ» انتخاب شود، هیچ چیزی اصلاً روی دیسک خروجی داده نمیشود - حتی نتایج شبیهسازی نیز نوشته نمیشوند. وقتی «همهچیز را روی دیسک بنویس» انتخاب شود، شبیهسازی همهچیز را روی دیسک dump میکند، بنابراین منحنیهای JV و همه متغیرهای داخلی حلگر روی دیسک نوشته میشوند تا کاربر بتواند بررسی کند که چگونه چگالیهای حامل، ترازهای فرمی، پتانسیلها و غیره در طول شبیهسازی تغییر میکنند (بخش 19.1 را ببینید). گزینه دوم در زیر «جزئیات خروجی روی دیسک» که «توزیع تله را dump کن» نام دارد، توزیع تلهها را در فضای انرژی و مکان مینویسد. بخش [sec:trapmap] را ببینید.
پوشه Snapshots - dir
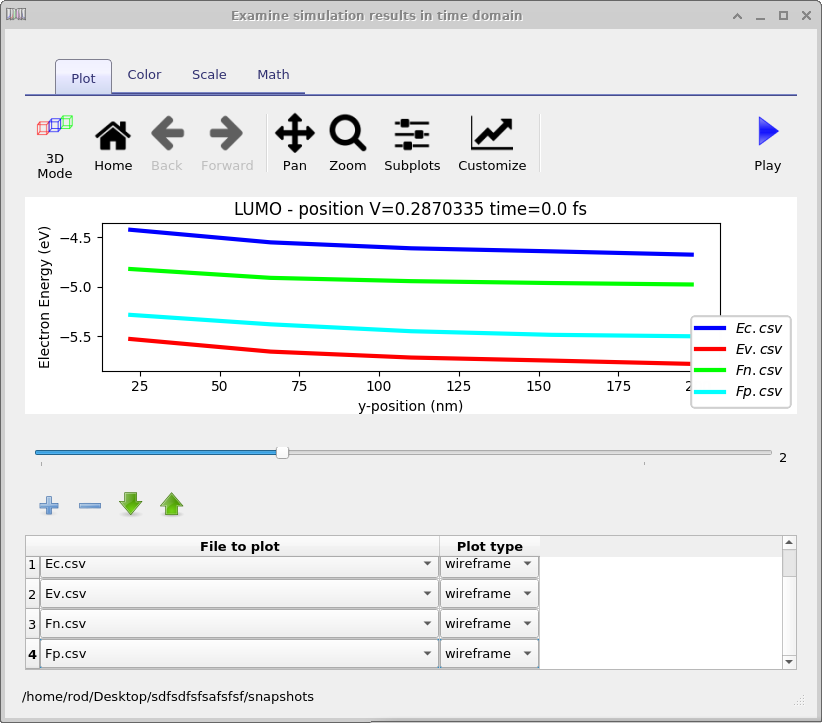
پوشه snapshots (شکل 19.2 را ببینید) به کاربر اجازه میدهد همه پارامترهای داخلی حلگر را رسم کند. برای مثال شکل 19.3 که در آن از ابزار snapshots برای رسم باند رسانش، باند ظرفیت و شبهترازهای فرمی بهصورت تابعی از ولتاژ استفاده میشود. از لغزنده میتوان برای مشاهده ولتاژهای مختلف استفاده کرد.
پوشه Trap_map - dir
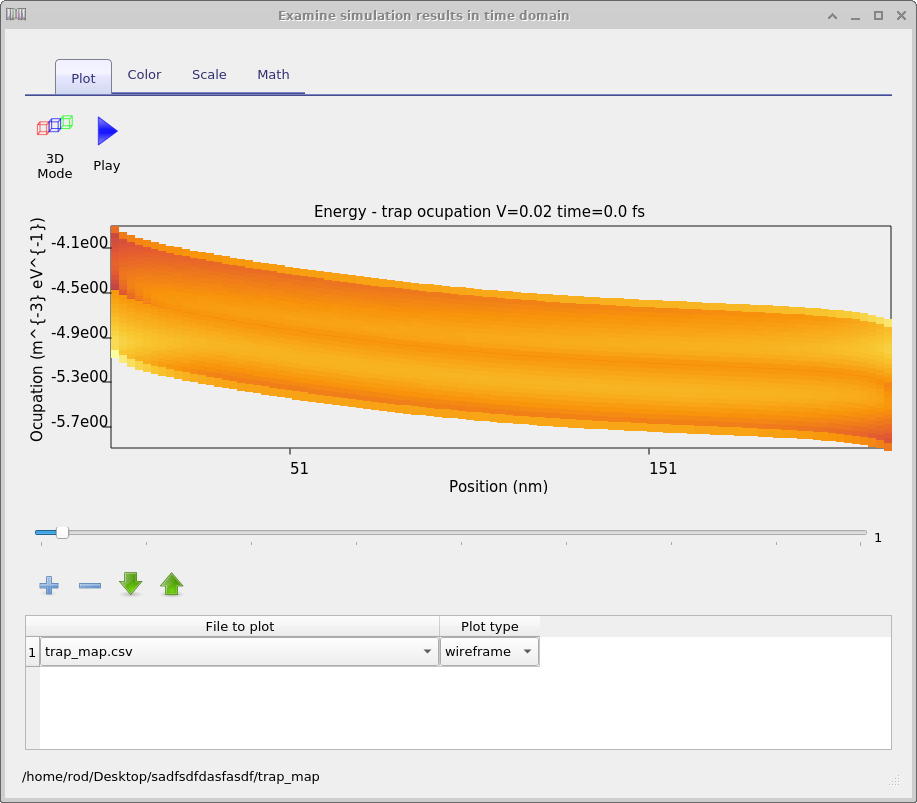
پوشه trap map شامل توزیع و چگالی حاملها در تلهها بهصورت تابعی از مکان و عمق انرژی است. یک نمونه در شکل 19.4 داده شده است [sec:trapmap]
اسنپشاتهای نوری - dir
شامل نتایج شبیهسازیهای نوری است.
Cache - dir
واداشتن یک رایانه به انجام محاسبات ریاضی، در مجموع کار کندی است. بسیار سریعتر است که نتایج از پیش محاسبه شوند و سپس پاسخها در یک جدول جستوجو ذخیره شوند. این کار میتواند محاسبات را بهطور قابلتوجهی سرعت دهد. پوشه cahce نتایج چنین پیشمحاسباتیهایی را ذخیره میکند، اگر بخواهید میتوانید آن را حذف کنید و OghmaNano فقط هنگام اجرا دوباره آن را خواهد ساخت.
پوشه Equilibrium
پیش از آنکه حلگر هر شبیهسازی را آغاز کند، معادلات دستگاه را در تاریکی و با بایاس اعمالی 0V حل میکند. نتیجه این محاسبه در این پوشه قرار میگیرد. دلیل عملی این کار آن است که روش نیوتن فقط زمانی کار میکند که برای هر مسئله یک حدس اولیه معقول به آن بدهید. بنابراین برای شروع حلگر، چگالیهای حامل را در 0V و در تاریکی حدس میزنیم، سپس از روش نیوتن برای محاسبه پروفایلهای دقیق چگالی حامل در 0V و در تاریکی استفاده میکنیم (نتایج در پوشه equilibrium ذخیره میشوند)، سپس از این نقطه میتوانیم راه خود را به سمت حلهای دیگر، مثلاً در +1V در نور، ادامه دهیم.
شبیهسازی نوری
| توکن JSON | معنی | واحدها | مرجع |
|---|---|---|---|
| \(J_{photo}\) | چگالی جریان نوری \(Am^{-2}\) | ||
| \(I_{photo}\) | جریان نوری \(A\) |
قالبهای فایل
تقریباً همه فایلهای ورودی و خروجی مرتبط با OghmaNano برای انسان قابل خواندن هستند، یعنی مستقیماً فایلهای متنیاند. همه فایلهای خروجی را میتوان مستقیماً در gnuplot/excel رسم کرد، همانطور که فایلهای ورودی را نیز میتوان. فایلهای خروجی در حال حاضر .dat نامیده میشوند، اما در واقع فقط فایلهای متنی هستند. همه فایلهای پیکربندی در قالب json هستند، بنابراین میتوان آنها را مستقیماً یا با استفاده از کتابخانه json پایتون ویرایش کرد.
فایلهای .dat
این نوع فایل یک فایل متنی ساده است که میتوان آن را به excel یا هر برنامه رسم دیگری وارد کرد. این فایل شامل دو ستون داده x و y است. همچنین یک پیشدرآمد در فایل وجود دارد که شامل اطلاعاتی مانند واحدها و غیره است. OghmaNano در حال گذار از فایلهای .dat به فایلهای .csv است.
فایلهای .csv
این یک فایل csv ساده است همانگونه که انتظار دارید و میتوان آن را به هر ویرایشگر متنی وارد کرد. خط اول فایل یک رشته json شامل اطلاعاتی مانند واحدها و غیره است. میتوانید این را نادیده بگیرید. خط دوم فایل دادههای x/y را به شکلی قابل خواندن برای انسان توصیف میکند و سپس بقیه فایل شامل دادهها است.
فایلهای .csv باینری - فایلهایی که برای انسان قابل خواندن نیستند
در برخی موارد dump کردن فایلهای متنی عملی نیست. نمونه آن هنگام کار با ساختارهای 3D است. در این حالت OghmaNano همان سرآیند json مورد استفاده در فایل csv را dump میکند و سپس مجموعهای از floatهای C را که نشاندهنده داده هستند dump میکند.