Editor de hardware

Todos los programas informáticos, incluido OghmaNano, se ejecutan en hardware físico de computación. Hay muchas combinaciones de hardware que puede haber en cualquier ordenador; algunos ordenadores tienen un gran número de núcleos de CPU, mientras que otros solo tienen uno. Asimismo, los ordenadores vienen con distintas cantidades de memoria, espacio en disco duro y GPU. Para ayudar al usuario a sacar el máximo partido de OghmaNano, existe un editor de hardware donde el usuario puede configurar cómo se comporta OghmaNano en cualquier ordenador dado. Se puede acceder a este a través de la ventana de la pestaña de simulación (??).
Si hace clic en esto, aparecerá la ventana del editor de hardware (??).
La ventana de hardware está compuesta por varias pestañas que permiten al usuario editar la configuración y también realizar benchmarks de su dispositivo.
Pestaña de configuración de CPU/GPU
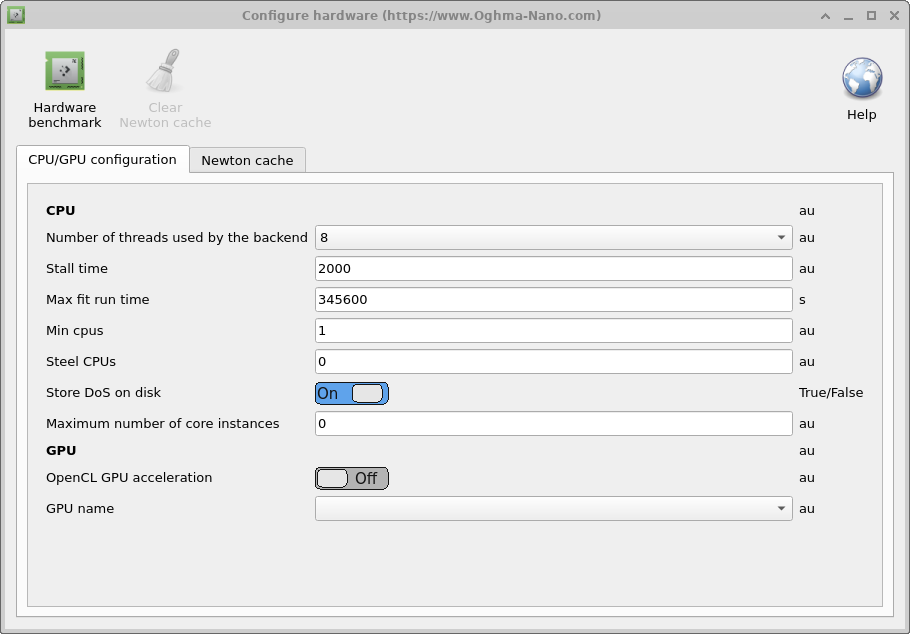
Esta pestaña se utiliza para configurar cómo OghmaNano interactúa con la GPU y la CPU; se describe en la tabla siguiente. Como se describe detalladamente en otras partes de este manual, hay dos partes en OghmaNano: está oghma_core.exe, que es el backend computacional, y está oghma_gui.exe, que es la interfaz gráfica de usuario; aquí puede ajustarse con precisión cómo se comportan ambas partes del modelo.
- Número de hilos utilizados por el backend: Este es el número máximo de hilos que OghmaNano oghma_core.exe puede utilizar. Esto determina: el número de ajustes simultáneos que pueden ejecutarse; el número máximo de simulaciones de optimización que pueden ejecutarse al mismo tiempo; el número máximo de hilos que se utilizan para simulaciones FDTD; el número máximo de archivos de caché DoS que pueden generarse al mismo tiempo; el número de puntos de dominio de frecuencia que pueden ejecutarse al mismo tiempo.
- Número máximo de instancias del núcleo: Esto establece el número máximo de instancias de oghma_core.exe que pueden iniciarse desde la GUI. Si se está ejecutando un barrido de parámetros, esto controlará el número máximo de simulaciones simultáneas que pueden realizarse al mismo tiempo. Si el valor de Número de hilos utilizados por el backend se ha establecido en 4 y se está realizando una simulación FDTD, entonces si se establece Número máximo de instancias del núcleo en 8, la GUI generará 8 instancias de oghma_core.exe usando cada una 4 hilos, por lo que se necesitarán 32 núcleos de CPU.
- Tiempo de bloqueo: A veces, al ejecutar OghmaNano sin supervisión en un superordenador, puede dejar de ejecutarse, posiblemente debido a un error de E/S o a un error de red. Esta opción puede utilizarse para establecer la duración máxima de una única simulación. Por simulación única me refiero a una sola curva JV, una sola simulación en dominio temporal o una sola simulación en dominio de frecuencia, pero no a un ajuste completo que implicará ejecutar miles de simulaciones individuales). Así, con un valor de 2000 segundos, el solucionador finalizará si, por ejemplo, una sola simulación JV tarda más de 2000 segundos. En realidad, cualquier simulación individual debería tardar solo unos pocos segundos, por lo que esta opción actúa como un tope rígido si algo ha ido muy mal.
- Tiempo máximo de ejecución del ajuste: Este es el tiempo máximo que oghma_core.exe puede permanecer en memoria. Si alguna simulación o ajuste tarda más que este valor, se terminará; de nuevo, esto es un tope para evitar que las simulaciones se ejecuten indefinidamente. El valor por defecto es 4 días.
- Robar CPUs: A veces, al ejecutar OghmaNano en un PC compartido, se inicia una simulación cuando otro usuario está utilizando un número significativo de núcleos. Al cabo de un tiempo, las simulaciones del otro usuario terminarán dejando el ordenador con CPUs inactivas. Si esta opción está establecida en True, entonces OghmaNano monitorizará el número de CPUs libres y, si hay más disponibles, las utilizará.
- CPUs mínimas: Se usa con la opción anterior Robar CPUs para establecer el número mínimo de CPUs que se utilizarán.
- Almacenar DoS en disco: OghmaNano almacena tablas de consulta en disco para acelerar las simulaciones; si esta opción se establece en false, estas tablas de consulta no se almacenarán.
- Aceleración GPU OpenCL: Esto habilita o deshabilita la aceleración por GPU; se utiliza principalmente durante las simulaciones FDTD.
- Nombre de la GPU: Selecciona la GPU que se utilizará.
Caché de Newton
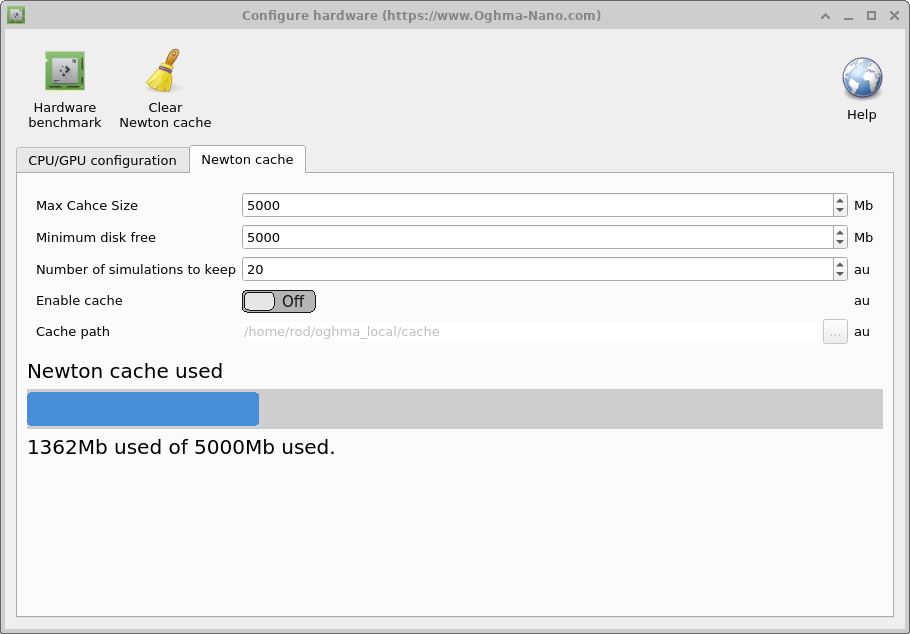
Al ejecutar simulaciones con un número significativo de EDO, como dispositivos 1D con muchos estados de trampa y un gran número de puntos espaciales, o al ejecutar simulaciones OFET 2D, cada paso de voltaje puede tardar bastante en calcularse. Esto se debe a que el solucionador debe resolver cada paso de voltaje usando el método de Newton hasta que converja. Para cada paso del solucionador debe construirse el Jacobiano, invertirse la matriz, multiplicarse por los residuos y calcularse las actualizaciones de todas las variables del solucionador. Esto puede consumir una cantidad significativa de tiempo por paso (2000 ms). Un enfoque para evitar este procedimiento es almacenar respuestas calculadas previamente en disco y luego, cuando el usuario pide al solucionador que calcule un problema ya calculado, la respuesta puede recuperarse en lugar de recalcularse. Esto es muy útil en el diseño de OLED, donde se intenta optimizar la estructura óptica del dispositivo pero se deja sin cambios la estructura eléctrica. Se pueden ejecutar nuevas simulaciones ópticas con soluciones eléctricas ya precalculadas. Las opciones de configuración se muestran en la tabla siguiente.
Hay una sobrecarga asociada al uso de la caché de Newton, así que solo la recomendaría cuando resolver el problema eléctrico sea realmente muy lento. Técnicamente, la caché de Newton funciona tomando la suma MD5 de los niveles de Fermi y de los potenciales para generar un hash del problema eléctrico. Esto se compara después con lo que existe en disco. Si se encuentra una respuesta precalculada, los niveles de Fermi/potenciales se actualizan a los valores encontrados en disco. La caché se almacena en la caché local de oghma_local; cada solución previamente resuelta se almacena como un nuevo archivo binario. Cada ejecución de simulación genera un archivo índice donde se almacenan todas las sumas MD5 de esa simulación. Una vez que la caché se llena, OghmaNano elimina resultados de simulación por lotes basándose en los archivos índice.
- Tamaño máximo de caché: Establece el tamaño máximo de la caché en Mb. Recomendaría alrededor de 1 Gb.
- Espacio libre mínimo en disco: Establece la cantidad mínima de espacio en disco necesaria para usar la caché; esta opción está diseñada para evitar que la caché llene el disco. La ajustaría a alrededor de 5 Gb.
- Número de simulaciones a conservar: Esto establecerá el número máximo de ejecuciones de simulación que se mantendrán; lo ajustaría entre 20 y 100.
- Habilitar caché: Esto habilita o deshabilita la caché de Newton; la opción por defecto y recomendada es False.
Benchmark de hardware
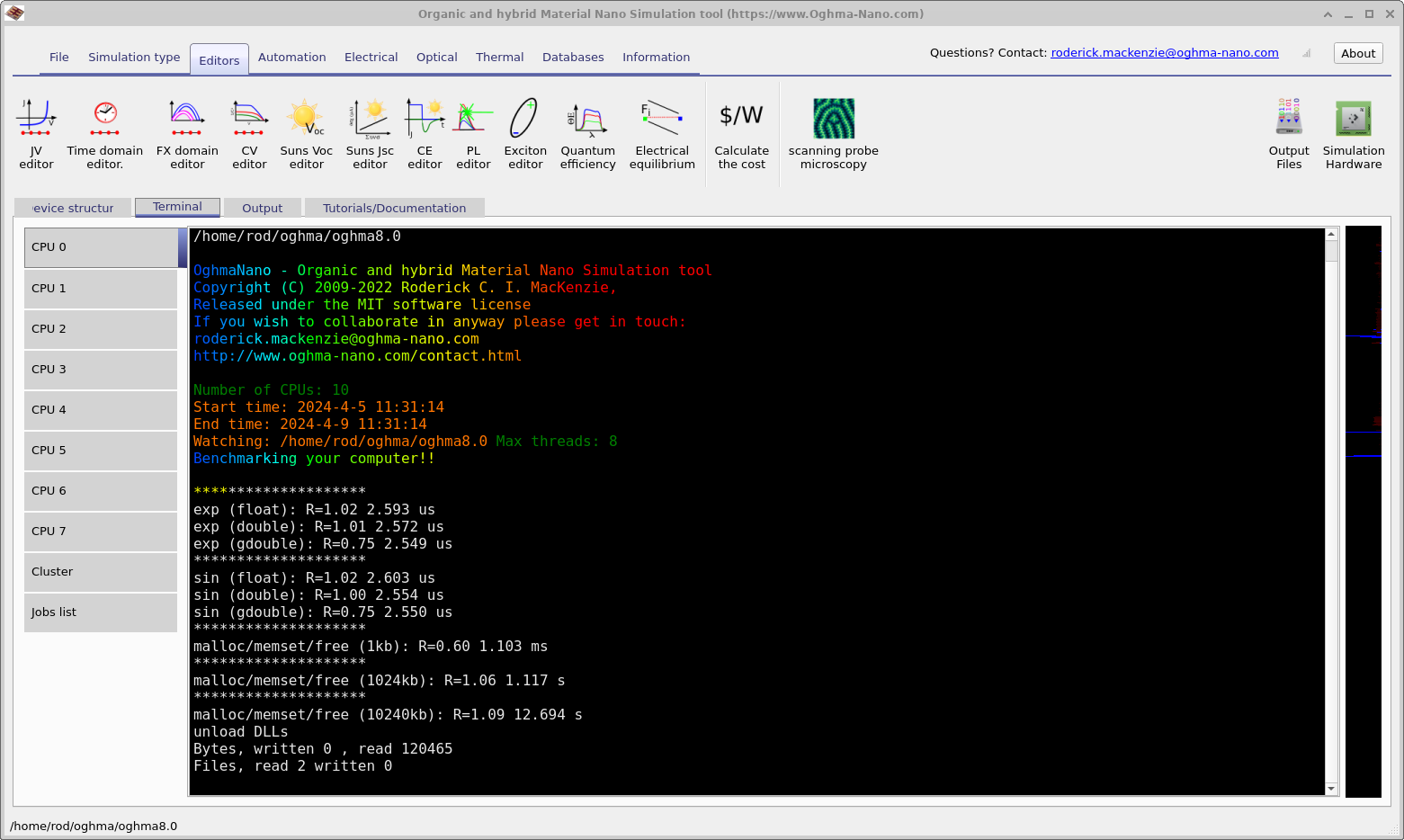
En la parte superior izquierda de la ventana de hardware (??) hay un botón llamado Hardware benchmark. Si se hace clic en él, entonces OghmaNano realizará un benchmark de su hardware; el resultado de dicho benchmark puede verse en (??). Esto ejecuta benchmarks de la capacidad de sus CPU para calcular sin,exp y asignar/desasignar memoria en bloques. Muestra cuánto tiempo tardó en realizar unos pocos miles de operaciones, así como un valor R (también conocido como Roderick). Este se define como R=Tiempo empleado en realizar el cálculo en su PC/Tiempo empleado en realizar el cálculo en mi PC. Por tanto, valores menores significan que su PC es más rápido que el mío. Mi PC es un Intel(R) Core(TM) i7-4900MQ CPU @ 2.80GHz en un Lenovo ThinkPad de 2017. Por lo tanto, la mayoría de los ordenadores modernos deberían ser más rápidos. Si tiene un buen rendimiento de CPU pero sus simulaciones se ejecutan más despacio que mis vídeos de YouTube, esto se debe invariablemente a una mala velocidad de E/S, causada por antivirus, almacenar las simulaciones en OneDrive, usar unidades de red, usar almacenamiento USB lento, etc.