Editor de hardware

Todos os programas de computador, incluindo o OghmaNano, são executados em hardware físico de computação. Existem muitas combinações de hardware que podem estar em qualquer computador; alguns computadores têm um grande número de núcleos de CPU, enquanto outros têm apenas um. Da mesma forma, os computadores vêm com diferentes quantidades de memória, espaço em disco rígido e GPUs. Para ajudar o usuário a obter o melhor do OghmaNano, existe um editor de hardware no qual o usuário pode configurar como o OghmaNano se comporta em um determinado computador. Isso pode ser acessado por meio da janela da aba de simulação (??).
Se você clicar nisso, a janela do editor de hardware será exibida (??).
A janela de hardware é composta por várias abas que permitem ao usuário editar a configuração e também fazer benchmark do seu dispositivo.
Aba de configuração CPU/GPU
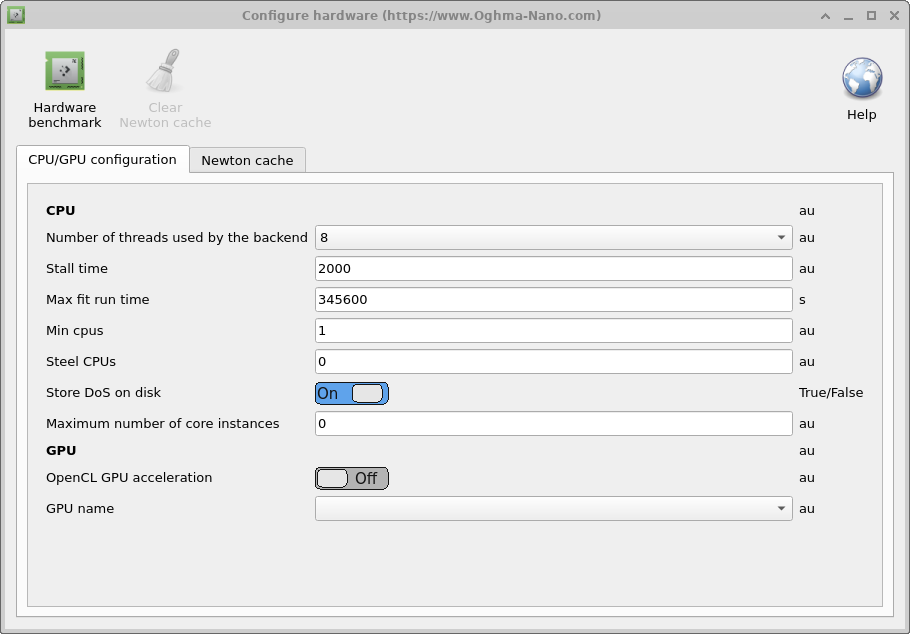
Esta aba é usada para configurar como o OghmaNano interage com a GPU e a CPU; ela é descrita na tabela abaixo. Como descrito em outras partes deste manual em detalhe, há duas partes no OghmaNano: existe o oghma_core.exe, que é o back end computacional, e existe o oghma_gui.exe, que é a interface gráfica do usuário; como ambas essas partes do modelo se comportam pode ser ajustado aqui.
- Número de threads usados pelo backend: Este é o número máximo de threads que o OghmaNano oghma_core.exe pode usar. Isso determina: o número de ajustes simultâneos que podem ser executados; o número máximo de simulações de otimização que podem ser executadas ao mesmo tempo; o número máximo de threads usados para simulações FDTD; o número máximo de arquivos de cache DoS que podem ser gerados ao mesmo tempo; o número de pontos do domínio de frequência que podem ser executados ao mesmo tempo.
- Número máximo de instâncias do core: Define o número máximo de instâncias de oghma_core.exe que podem ser iniciadas pela GUI. Se alguém estiver executando uma varredura de parâmetros, isso controlará o número máximo de simulações simultâneas que podem ser realizadas ao mesmo tempo. Se os valores de Número de threads usados pelo backend tiverem sido definidos como 4 e alguém estiver realizando uma simulação FDTD, então se definir Número máximo de instâncias do core como 8, a GUI criará 8 instâncias de oghma_core.exe, cada uma usando 4 threads; assim, serão necessários 32 núcleos de CPU.
- Tempo de stall: Às vezes, ao executar o OghmaNano em um supercomputador sem supervisão, ele pode parar de executar, possivelmente por causa de um erro de IO ou de rede. Esta opção pode ser usada para definir a duração máxima de uma única simulação. Por simulação única, quero dizer uma única curva JV, uma única simulação de domínio do tempo ou uma única simulação de domínio de frequência, mas não um ajuste completo, que envolverá a execução de milhares de simulações individuais.) Portanto, com um valor de 2000 segundos, o solver será encerrado se, por exemplo, uma única simulação JV demorar mais de 2000 segundos. Na realidade, qualquer simulação individual deve levar apenas alguns segundos, então esta opção atua como um limite rígido caso algo tenha dado muito errado.
- Tempo máximo de execução de ajuste: Este é o tempo máximo que o oghma_core.exe pode permanecer na memória. Se qualquer simulação ou ajuste demorar mais que esse valor, ele será encerrado; novamente, isso é uma proteção para impedir que as simulações executem para sempre. O valor padrão é 4 dias.
- Roubar CPUs: Às vezes, ao executar o OghmaNano em um PC compartilhado, alguém iniciará uma simulação enquanto outro usuário estiver usando um número significativo de núcleos. Depois de um tempo, as simulações do outro usuário terminarão de executar, deixando o computador com CPUs ociosas. Se esta opção estiver definida como True, então o OghmaNano irá monitorar o número de CPUs livres e, se mais ficarem disponíveis, irá usá-las.
- CPUs mínimas: Usado com a opção acima Roubar CPUs para definir o número mínimo de CPUs que serão usadas.
- Armazenar DoS em disco: O OghmaNano armazena tabelas de consulta em disco para acelerar simulações; se esta opção estiver definida como false, essas tabelas de consulta não serão armazenadas.
- Aceleração OpenCL GPU: Isso habilita ou desabilita a aceleração por GPU; isso é usado principalmente durante as simulações FDTD.
- Nome da GPU: Seleciona a GPU a ser usada.
Cache de Newton
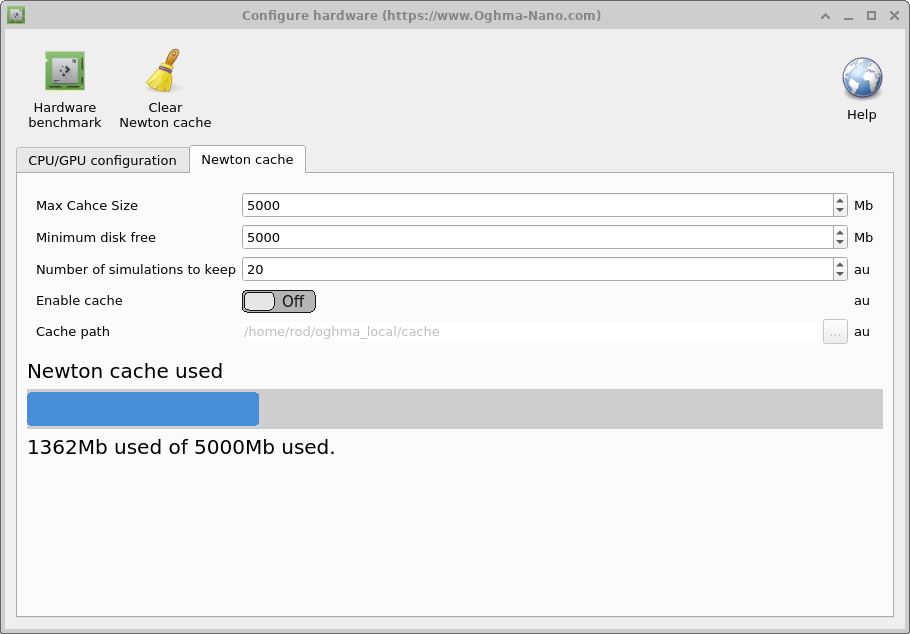
Ao executar simulações com um número significativo de ODEs, como dispositivos 1D com muitos estados de armadilha e muitos pontos espaciais, ou ao executar simulações OFET 2D, cada passo de tensão pode levar algum tempo para ser calculado. Isso acontece porque o solver deve resolver cada passo de tensão usando o método de Newton até convergir. Para cada passo do solver, o Jacobiano deve ser construído, a matriz invertida multiplicada pelos resíduos e as atualizações de todas as variáveis do solver calculadas. Isso pode levar uma quantidade significativa de tempo por passo (2000ms). Uma abordagem para contornar isso é armazenar respostas previamente calculadas em disco e então, quando o usuário pedir ao solver para calcular um problema já calculado, a resposta pode ser recuperada em vez de recalculada. Isso é muito útil no design de OLEDs, onde se está tentando otimizar a estrutura óptica do dispositivo, mas deixando a estrutura elétrica inalterada. Pode-se executar novas simulações ópticas com soluções elétricas já pré-calculadas. As opções de configuração são exibidas na tabela abaixo.
Existe um overhead ao usar o Cache de Newton, então eu só o recomendaria quando resolver o problema elétrico for realmente muito lento. Tecnicamente, o cache de Newton funciona tirando a soma MD5 dos níveis de Fermi e dos potenciais para gerar um hash do problema elétrico. Isso é então comparado ao que existe em disco. Se uma resposta pré-calculada for encontrada, os níveis de Fermi/potenciais são atualizados para os valores encontrados em disco. O cache é armazenado em oghma_local cache; cada solução pré-resolvida é armazenada como um novo arquivo binário. Cada execução de simulação gera um arquivo de índice onde todas as somas MD5 dessa simulação são armazenadas. Quando o cache fica cheio, o OghmaNano apaga resultados de simulação em lotes com base nos arquivos de índice.
- Tamanho máximo do cache: Define o tamanho máximo do cache em Mb. Eu recomendaria cerca de 1Gb.
- Espaço livre mínimo em disco: Define a quantidade mínima de espaço em disco necessária para usar o cache; esta opção foi projetada para impedir que o cache encha o disco. Eu definiria em torno de 5Gb.
- Número de simulações a manter: Isso definirá o número máximo de execuções de simulação a manter. Eu definiria entre 20 e 100.
- Habilitar cache: Isso habilita ou desabilita o Cache de Newton; a opção padrão e recomendada é False.
Benchmark de hardware
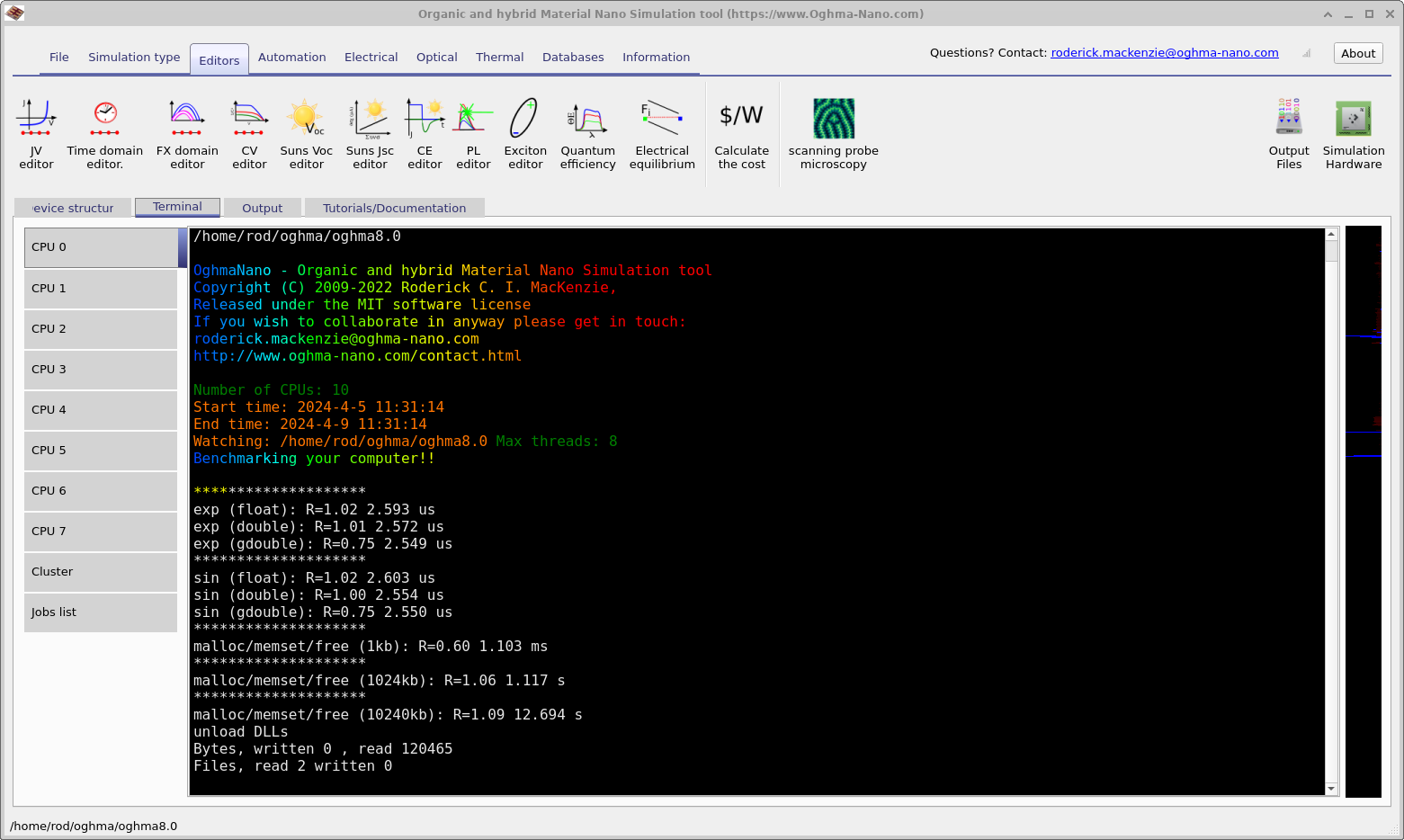
No canto superior esquerdo da janela de hardware (??) há um botão chamado Hardware benchmark. Se ele for clicado, então o OghmaNano fará benchmark do seu hardware; o resultado de tal benchmark pode ser visto em (??). Isso executa benchmarks da capacidade das suas CPUs de calcular sin,exp e alocar/desalocar memória em blocos. Ele exibe quanto tempo levou para fazer alguns milhares de operações, bem como um valor R (também conhecido como valor Roderick). Isso é definido como R=Tempo gasto para fazer o cálculo no seu PC/Tempo gasto para fazer o cálculo no meu PC. Assim, valores menores significam que seu PC é mais rápido que o meu. Meu PC é um Intel(R) Core(TM) i7-4900MQ CPU @ 2.80GHz em um Lenovo thinkpad de 2017. Portanto, a maioria dos computadores modernos deve ser mais rápida. Se você tiver bom desempenho de CPU, mas suas simulações estiverem executando mais lentamente do que nos meus vídeos do YouTube, isso invariavelmente ocorre devido à baixa velocidade de IO, causada por antivírus, armazenamento das simulações no OneDrive, uso de unidades de rede, uso de armazenamento USB lento etc.