ハードウェアエディタ

OghmaNano を含むすべてのコンピュータプログラムは、物理的な計算ハードウェア上で動作します。どのコンピュータにも 多くのハードウェア構成の組み合わせが存在し、あるコンピュータは多数の CPU コアを持ち、別のものは 1 つしか持ちません。 同様に、コンピュータには異なる量のメモリ、ハードディスク容量、GPU が搭載されています。ユーザーが OghmaNano を最大限に活用できるように、ハードウェアエディタが用意されており、任意の コンピュータ上で OghmaNano がどのように動作するかを設定できます。これはシミュレーションタブウィンドウからアクセスできます (??)。
これをクリックすると、ハードウェアエディタウィンドウが表示されます(??)。
ハードウェアウィンドウはさまざまなタブで構成されており、ユーザーが設定を編集したり、 デバイスのベンチマークを実行したりできます。
CPU/GPU 設定タブ
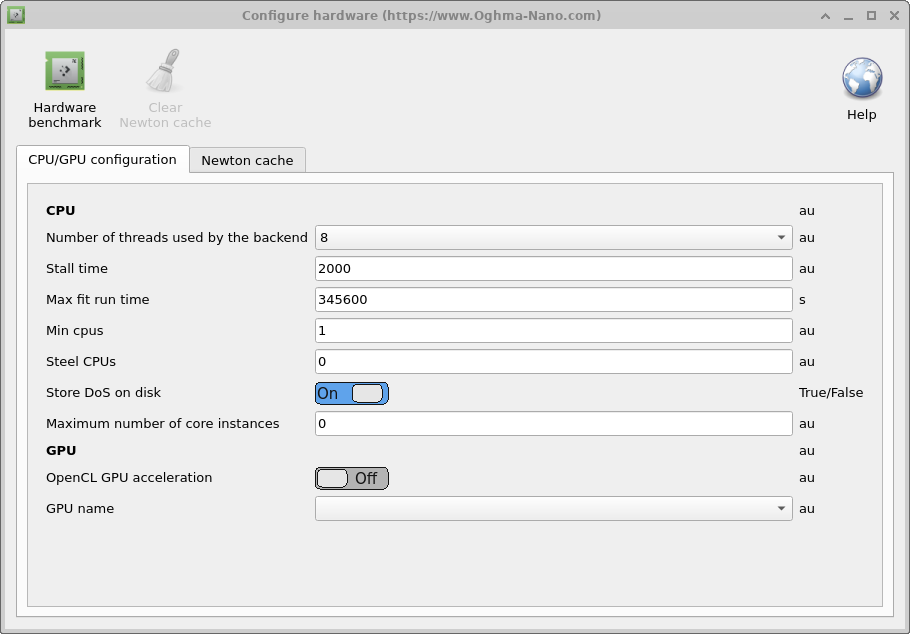
このタブは、OghmaNano が GPU および CPU とどのように相互作用するかを設定するために使用されます。これは以下の表で説明されています。 このマニュアルの他の部分で詳しく説明しているように、OghmaNano には 2 つの部分があります。すなわち、計算バックエンドである oghma_core.exe と、 グラフィカルユーザーインターフェースである oghma_gui.exe です。 モデルのこれら両方の部分の挙動をここで微調整できます。
- バックエンドで使用されるスレッド数: これは OghmaNano oghma_core.exe が使用できる最大スレッド数です。これにより、同時に実行できるフィットの数、 同時に実行できる最適化シミュレーションの最大数、FDTD シミュレーションで使用される最大スレッド数、同時に生成できる DoS キャッシュファイルの最大数、周波数領域 点を同時に実行できる数が決まります。
- 最大 core インスタンス数: これは GUI によって起動できる oghma_core.exe インスタンスの最大数を設定します。 パラメータスキャンを実行している場合、これは 同時に実行できるシミュレーションの最大数を制御します。もし バックエンドで使用されるスレッド数 の値が 4 に設定されていて、 FDTD シミュレーションを実行しているときに、最大 core インスタンス数 を 8 に設定すると、 GUI はそれぞれ 4 スレッドを使用する 8 個の oghma_core.exe インスタンスを起動するため、 32 個の CPU コアが必要になります。
- Stall time: スーパーコンピュータ上で OghmaNano を無人実行している場合、 IO エラーやネットワークエラーなどが原因で実行が停止することがあります。 このオプションは、単一シミュレーションの最大長を設定するために使用できます。ここでいう単一シミュレーションとは、 単一の JV 曲線、単一の時間領域シミュレーション、または単一の周波数領域シミュレーションを意味し、 何千もの個別シミュレーションを伴う全体のフィットは含みません。したがって、 値を 2000 秒にすると、たとえば単一の JV シミュレーションに 2000 秒以上かかる場合、ソルバは終了します。実際には個々のシミュレーションは数秒しかかからないはずなので、 このオプションは何かが非常にうまくいっていない場合のハードバックストップとして機能します。
- Max fit run time: これは oghma_core.exe がメモリ内に常駐できる最大時間です。いずれのシミュレーション またはフィットでもこの値より長くかかる場合は終了されます。これもまた、シミュレーションが 永遠に実行されるのを防ぐためのバックストップです。デフォルト値は 4 日です。
- Steel CPUs: 共有 PC 上で OghmaNano を実行している際、他のユーザーがかなりの数のコアを使用しているときに シミュレーションを開始することがあります。しばらくすると他のユーザーのシミュレーションは終了し、 コンピュータにはアイドル状態の CPU が残ります。このオプションを True に設定すると、 OghmaNano は空いている CPU の数を監視し、さらに利用可能になればそれらを使用します。
- Min CPUs: 上の Steel CPUs オプションとともに使用し、 使用する CPU の最小数を設定します。
- Store DoS on disk: OghmaNano はシミュレーションを高速化するためにルックアップテーブルをディスクに保存します。 このオプションを false に設定すると、これらのルックアップテーブルは保存されません。
- OpenCL GPU acceleration: これは GPU アクセラレーションを有効または無効にします。主に FDTD シミュレーション中に使用されます。
- GPU name: 使用する GPU を選択します。
Newton キャッシュ
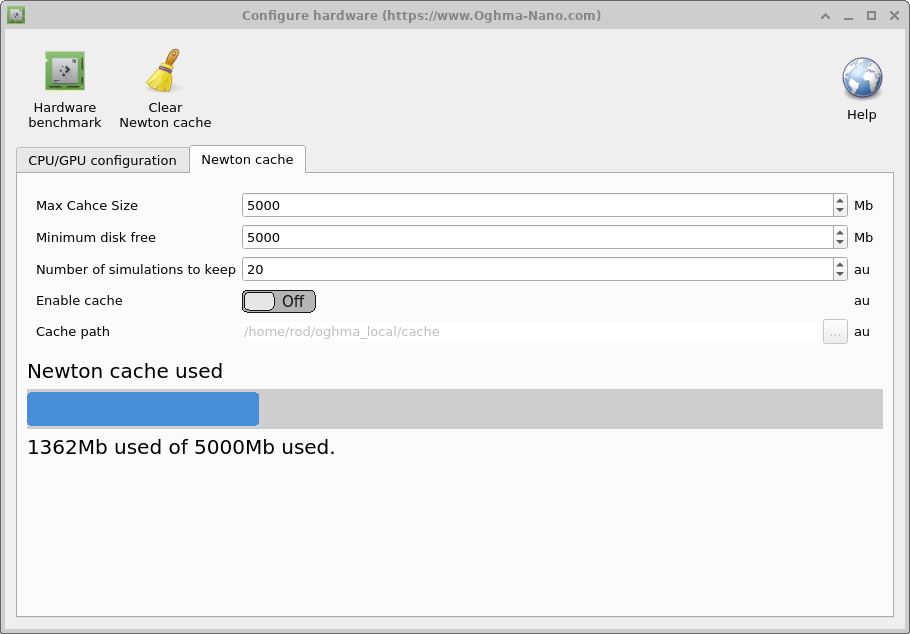
多数の ODE を持つシミュレーション、たとえば多数のトラップ状態と多数の空間点を持つ 1D デバイス、 または 2D OFET シミュレーションを実行する場合、各電圧ステップの計算に時間がかかることがあります。これは、 ソルバが収束するまで Newton 法を用いて各電圧ステップを解かなければならないためです。各ソルバステップごとに、 Jacobian を構築し、行列を反転して残差と掛け合わせ、 すべてのソルバ変数の更新を計算しなければなりません。これには 1 ステップあたりかなりの時間(2000ms)がかかることがあります。 この方法を回避する 1 つのアプローチは、以前に計算した解をディスクに保存し、ユーザーがすでに 計算済みの問題をソルバに要求したときに、再計算する代わりにその解を呼び出すことです。これは OLED 設計で、 デバイスの光学構造を最適化しようとしているが電気構造は変更しない場合に非常に有用です。すでに 事前計算された電気解を用いて新しい光学シミュレーションを実行できます。設定オプションは以下の表に 表示されています。
Newton Cache の使用にはオーバーヘッドがあるため、電気問題の解法が本当に非常に遅い場合にのみ推奨します。 技術的には、Newton cache は Fermi 準位と ポテンシャルの MD5 和を取って電気問題のハッシュを生成することで機能します。これがディスク上に存在するものと比較されます。もし 事前計算された解が見つかれば、Fermi 準位/ポテンシャルはディスク上に見つかった値に更新されます。キャッシュは oghma_local cache に保存され、各事前解決済み解は新しいバイナリファイルとして保存されます。各シミュレーション実行では、 そのシミュレーションのすべての MD5 和を保存したインデックスファイルが生成されます。キャッシュが一杯になると、OghmaNano は インデックスファイルに基づいてシミュレーション結果をまとめて削除します。
- Maximum cache size: キャッシュの最大サイズを Mb 単位で設定します。1Gb 程度を推奨します。
- Minimum disk free: キャッシュを使用するために必要な最小ディスク空き容量を設定します。このオプションは キャッシュがディスクを埋め尽くすのを防ぐために設計されており、5Gb 程度に設定することを推奨します。
- Number of simulations to keep: 保持するシミュレーション実行の最大数を設定します。20 から 100 の間に 設定することを推奨します。
- Enable cache: Newton Cache を有効または無効にします。デフォルトかつ推奨オプションは False です。
ハードウェアベンチマーク
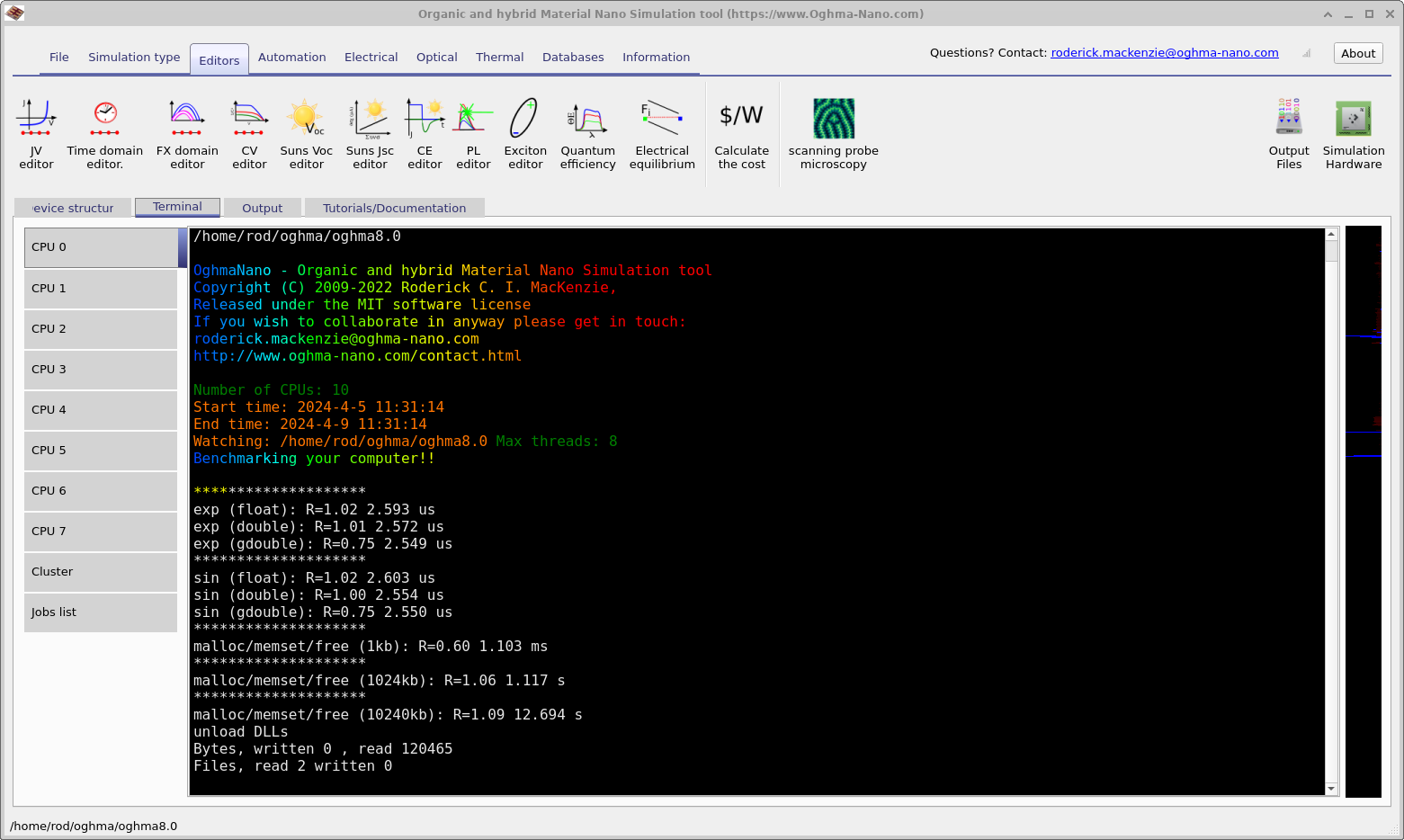
ハードウェアウィンドウの左上(??)には Hardware benchmark というボタンがあります。これをクリックすると、 OghmaNano はハードウェアをベンチマークし、その結果は(??)に示されています。これは CPU の sin、exp の計算能力およびブロック単位でのメモリ割り当て/解放能力をベンチマークします。 数千回の演算を行うのにかかった時間と、R(別名 Roderick)値を表示します。これは R=あなたの PC で計算にかかった時間/私の PC で計算にかかった時間 と定義されます。 したがって、値が小さいほどあなたの PC は私のものより速いことを意味します。私の PC は 2017 年製 Lenovo thinkpad の Intel(R) Core(TM) i7-4900MQ CPU @ 2.80GHz です。したがって、ほとんどの現代的なコンピュータはこれより速いはずです。 CPU 性能が良いのにシミュレーションが私の YouTube 動画より遅い場合、それはほとんど常に IO 速度の悪さによるもので、 ウイルス対策ソフト、OneDrive 上へのシミュレーション保存、 ネットワークドライブの使用、遅い USB ストレージの使用などが原因です。