実験データへのフィッティング
1. 概要
暗 JV 曲線にダイオード方程式をフィットさせて理想係数を抽出できるのと同様に、OghmaNano では完全なデバイスモデルを実験データへ直接フィットさせることができます。シミュレーションを測定結果に較正することで、自己無撞着な枠組みの中で、移動度、トラップ状態密度、接触抵抗、再結合係数といった物理的に意味のあるパラメータを回復できます。単純な解析式と比べると、物理ベースのフィットは光学–電気結合を保持し、性能を支配する機構についてより豊かで信頼性の高い洞察を与えます。このチュートリアルでは、OghmaNano におけるフィッティングのワークフローを紹介し、変数の選び方、minimizer の選択方法、および効率的で再現性のあるフィットの実行方法を示します。
2. 最初のフィット
OghmaNano には、モデルを実験データにフィットする方法を示すいくつかのデモシミュレーションが含まれています。そのうちの 1 つは、 単純な drift–diffusion モデルを例として使用しています。これにアクセスするには、File リボンの New simulation アイコンをクリックして New simulation ウィンドウを開きます(Figure ??)。 ここから、Scripting and fitting カテゴリをダブルクリックして、Figure ?? に 示すフォルダを開きます。 Fitting and parameter extraction のサンプルを選択してデモプロジェクトを読み込みます。 開くと、単純な太陽電池シミュレーションが起動します(Figure ??)。 このデモは太陽電池に焦点を当てていますが、フィッティングエンジンは任意のシミュレーションと実験データセットに適用できます。
新しいシミュレーションを保存すると、メインシミュレーションウィンドウが表示されます(??)。 ここから、Automation リボン(赤で強調表示)に移動し、Fit to experiment アイコンを選択してフィッティングウィンドウ ?? にアクセスします。
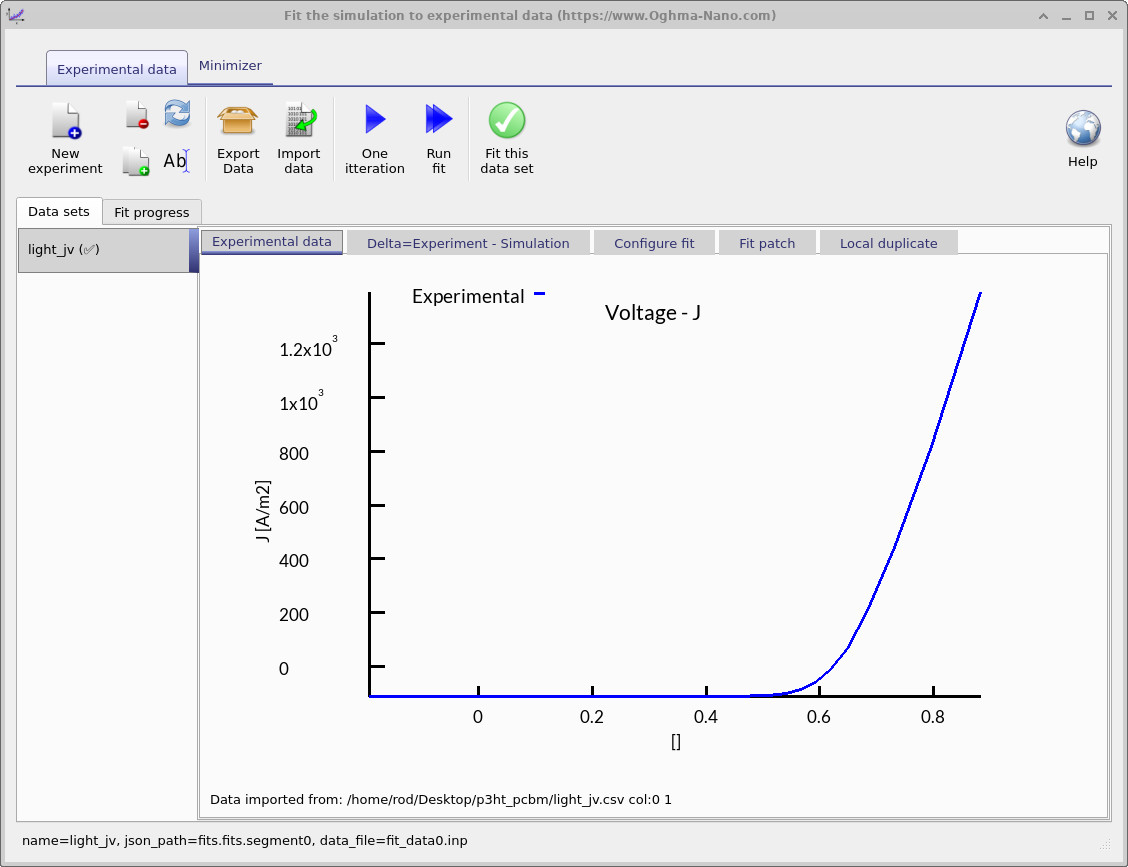
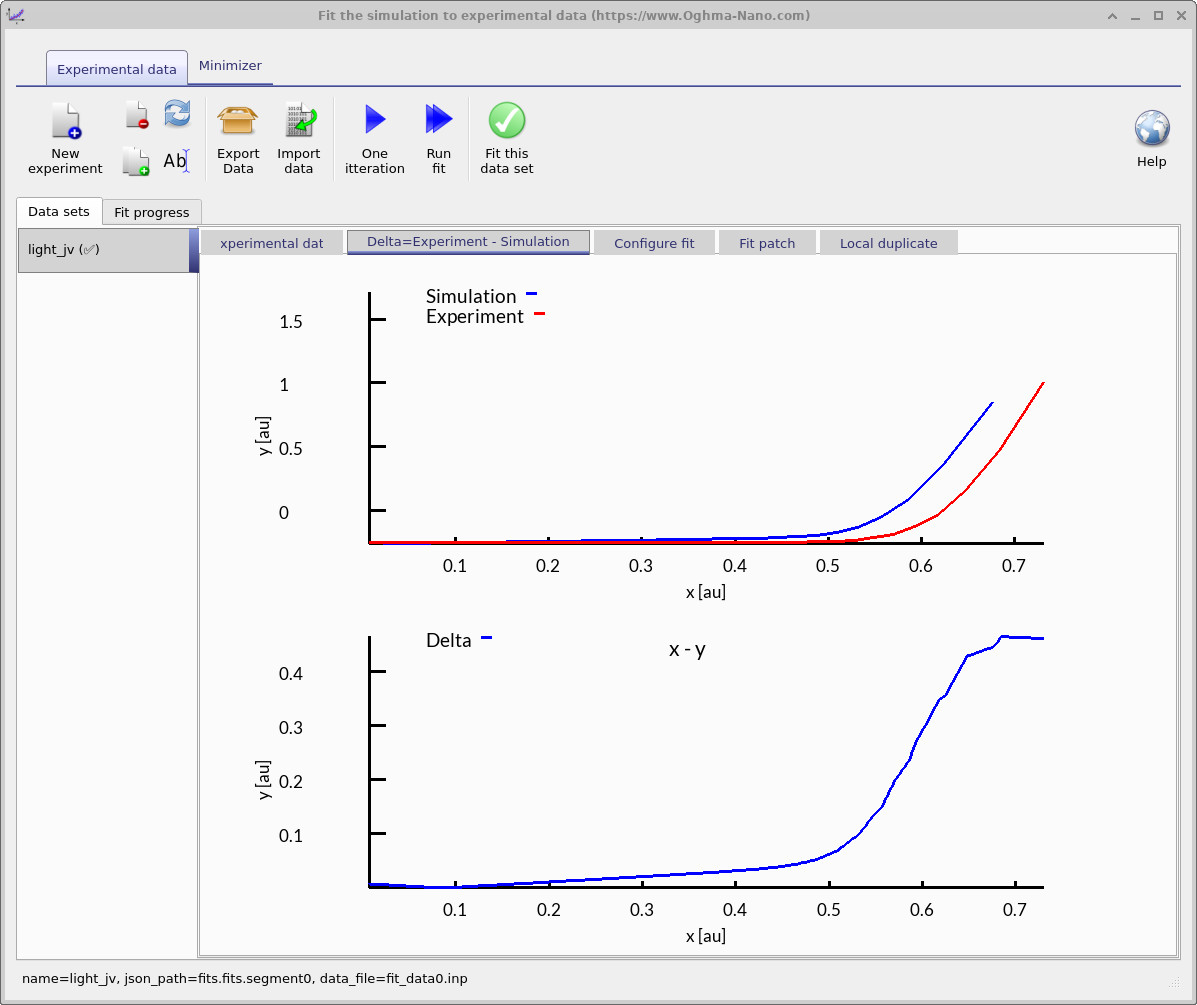
フィッティングウィンドウは、最適化の実行方法を制御します。ここでは、どの実験データセットを使用するか、 どのシミュレーション変数を調整するかを指定します。ここで示すように単一のデータセットにフィットすることも、 より強く制約されたパラメータ抽出のために複数のデータセットへ同時にフィットすることもできます。Figure ?? では、 青い線がフィッティングに使用される実験 JV 曲線を表しています。
💡 実践演習: フィッティングウィンドウの使用
- Task 1 – One iteration: One iteration ボタンをクリックしてフィッティング表示を更新します (??a)。 Delta = Experiment − Simulation タブでは、実験 JV(赤)に重ねてシミュレーション JV(青)が表示され、 加えて緑の delta 曲線が点ごとに \( \Delta(V) = J_{\mathrm{exp}}(V) - J_{\mathrm{sim}}(V) \) として定義されます。 良い出発点は、緑の曲線が電圧範囲全体でゼロに近い場合です。
-
Task 2 – Run fit:
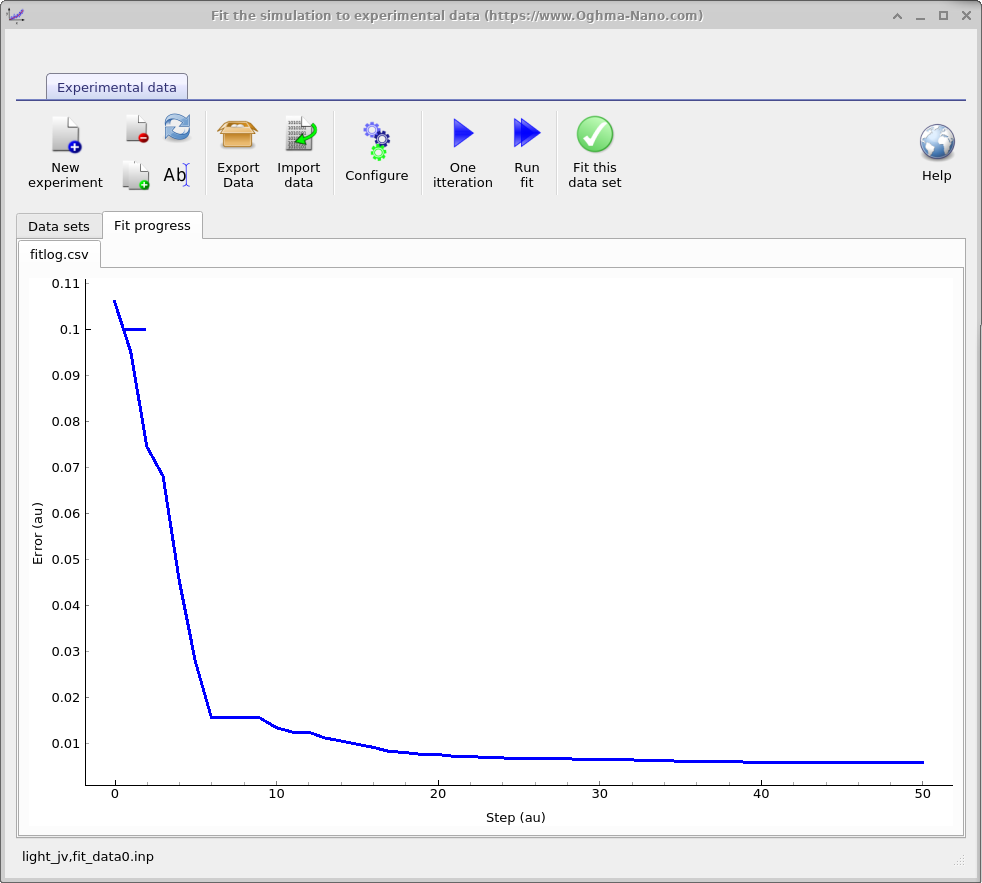
Run fit を押して自動 minimizer を開始します(もう一度押すと停止します)。
最初の数ステップでは誤差が一時的に増加することがありますが、その後シミュレーション曲線と
実験曲線が収束するにつれて低下するはずです。Fit progress タブに切り替えて
反復回数に対する誤差をプロットしてください
(??b)。このグラフは
外部でプロットできるように、シミュレーションディレクトリ内の
fitlog.csvにも保存されます。 一般的な環境では、この段階には約 30 秒かかります。
3. データの追加と削除
メインフィッティングウィンドウには、実験データの追加、管理、およびフィット方法を制御するコマンドのツールバーがあります。 これらのボタンにより、データセットのインポートまたは削除、 どのパラメータを変化させるかの設定、およびフィッティングプロセスの開始または停止が可能です。最も重要なオプションは次のとおりです:
- New experiment: フィッティングウィンドウに別の実験データセットを追加します。たとえば、 light JV 曲線と dark JV 曲線の両方を含めることができます。複数のデータセットに対してフィットすると、 抽出されるパラメータの信頼性は向上しますが、フィッティング処理は遅くなり、より難しくもなります。
- Delete experiment: 選択したデータセットをフィットから削除します。
- Clone experiment: 現在のデータセットの複製を作成します。
- Rename experiment: 選択したデータセットの名前を変更できます。
- Export data: 現在のフィットとデータを圧縮 zip ファイルとして保存します。
- Import data: 外部の実験データをフィッティングウィンドウに読み込みます(詳細は Import Wizard セクションを参照)。
- Configure: フィッティング中に調整される変数を定義する設定ウィンドウを開きます(以下で詳しく説明します)。
- One iteration: 単一のフィッティングステップを実行して、シミュレーションが実験データにどれだけ近いかを確認します。自動フィットを実行する前に、この オプションを使用してパラメータを手動で調整し、妥当な初期点を得ることを推奨します。
- Run fit: 自動フィッティングアルゴリズムを開始します。この処理はボタンを再度押して手動で停止するまで継続します。
- Fit this data set: 現在選択しているデータセットに対するフィッティングを有効または無効にします。
4. The minimizer ribbon
Minimizer リボンは、フィッティング中に使用される最適化アルゴリズムを制御します。このタブから、 適用する minimizer(たとえばデフォルトの Nelder–Mead downhill simplex)を選択し、 その設定を構成できます。リボンには、フィッティング変数の管理、パラメータの複製、および フィットを制約するための数式ルール適用のためのツールも含まれています。これらのオプションを調整することで、アルゴリズムが パラメータ空間をどのように探索するかを制御し、速度と精度のバランスを取り、 物理的に意味のある制約がフィッティング処理中に確実に強制されるようにできます。
5. フィットする変数の設定
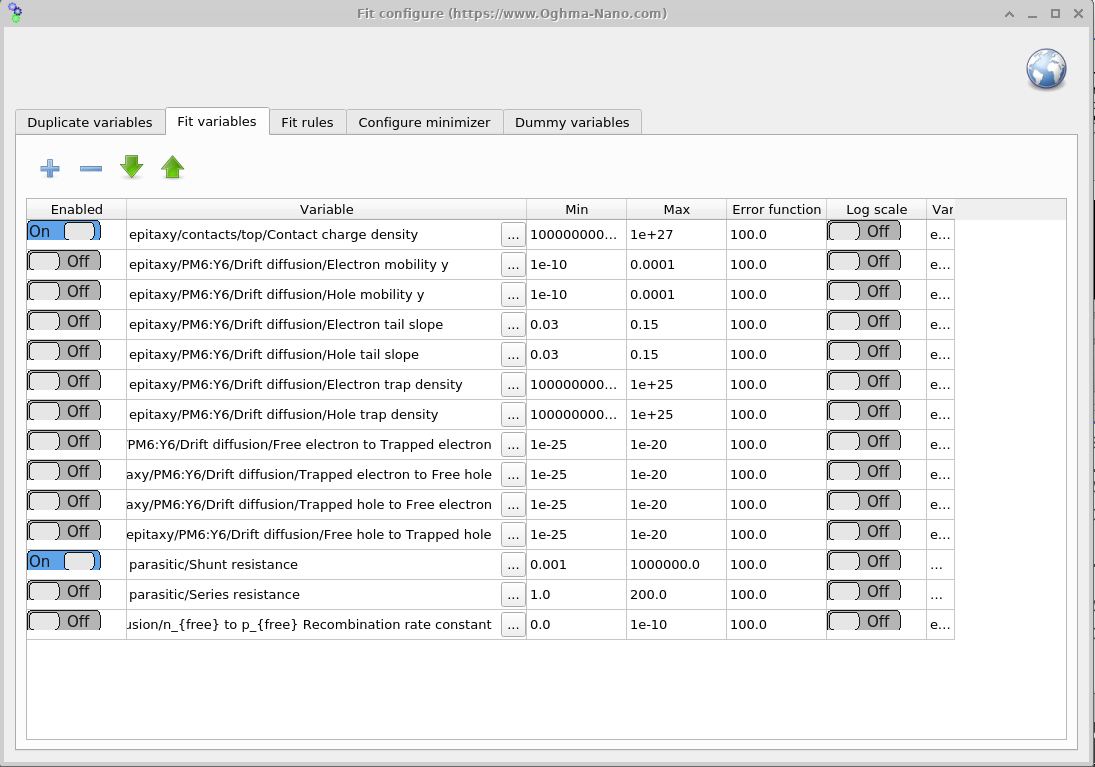
Fit variables ウィンドウを開くには、フィッティングウィンドウの Minimizer リボン (Figure ??)に移動し、 Fitting variables をクリックします。このパネル(Figure ??)では、 フィット中にどのパラメータを変化させるかを選び、その境界を設定できます。速度と頑健性のために、まずは 少数の対称パラメータから始めてください。妥当な初期フィットが得られてから、さらに追加したり(あるいは非対称性を導入したり)します。
Fit variables テーブルには 7 つの列があります: Enabled、Variable、 Min、Max、Error function、Log scale、および Variable (JSON)。
- Enabled: 変数のフィッティングをオンまたはオフにします。
- Variable: フィットされる変数へのパスを English で記述します。
- Min: 変数が取り得る最小値。
- Max: 変数が取り得る最大値。
- Error function: 変数が min–max 範囲外へ逸脱した場合に 総フィッティング誤差へ追加されるペナルティ。これによりアルゴリズムは実質的に 許容境界内へ 押し戻されます。
- Log scale: パラメータを対数スケールでフィットします。多くの 桁にわたる変数に有用で、範囲全体が探索されるようにします。
- Variable (JSON): 通常は非表示です。パラメータの完全なパスを
json形式で表します。バックエンドはこのパスを使用し、English パスは読みやすさのためだけであり、 常に厳密であるとは限りません。
6. 変数の複製
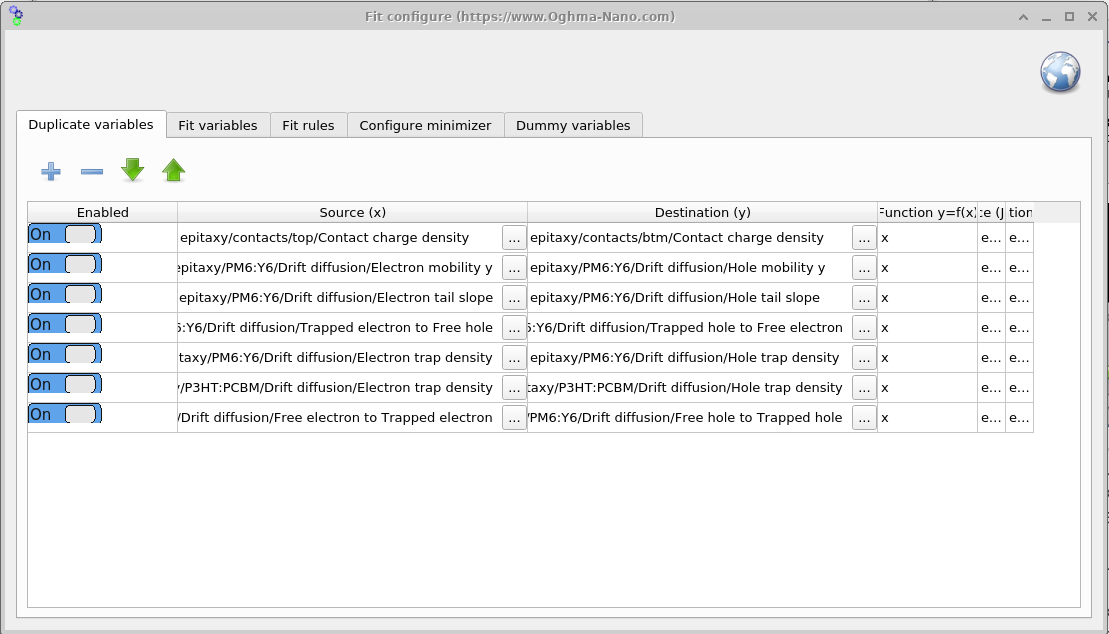
Duplicate variables ウィンドウを Minimizer リボン (??)から開きます。 このツールは、毎反復ごとに source パラメータを destination パラメータへミラーします。 対称デバイスの例では、電子側パラメータのみをフィットし、Duplicate variables を用いて その値を対応する正孔パラメータへコピーすることで、フィット全体を通してそれらを等しく保ちます (?? を参照)。
Function y = f(x) 列は、source 値 x が
destination y に書き込まれる前にどのように変換されるかを定義します。デフォルトの x は直接コピーを実行します。例として
2*x(値を 2 倍にする)や x + 0.05(オフセットを加える)も可能です。
7. Fit rules
Fit rules ウィンドウ(??)は Minimizer リボンからアクセスでき、フィッティングプロセスに数学的 制約を適用できます。ルールは、条件が破られるたびに誤差関数へペナルティを追加します。 たとえば、あるパラメータが常に別のパラメータより大きい必要があることを強制したり、 変数が許容範囲外へ逸脱した場合にペナルティを課したりできます。これによりフィットが物理的に意味のある状態に保たれ、 minimizer が非現実的なパラメータ組合せを探索するのを防ぎます。
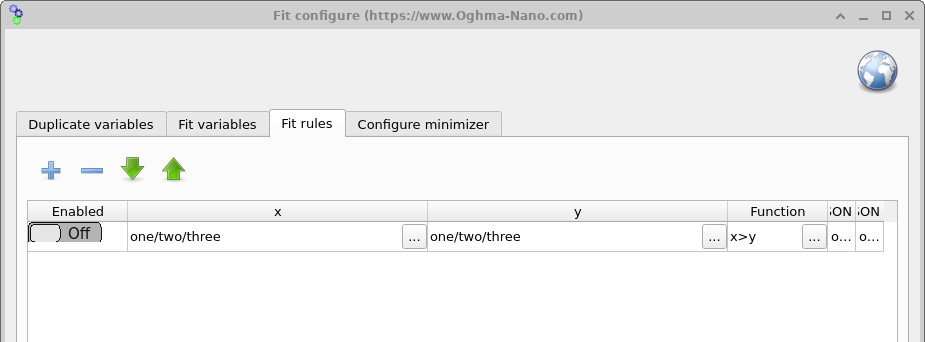
x > y のような制約を定義して、
パラメータ間の関係を強制できます。ルールが破られると追加誤差がフィットへ加えられ、
minimizer を有効なパラメータ空間領域へ導き戻します。
💡 フィッティングのための重要なヒントとコツ:
- 一般に、フィッティングは非常に根気と手動での微調整を要する難しいプロセスです。ボタンをクリックすれば ただ動くと期待しないでください — 良いフィットを得るには慎重に作業する必要があります。
- フィットがうまくいかない場合、デバイスについて置いた物理的仮定に何か問題がある可能性があります。 モデルは物理的に妥当なデータにしかフィットしないため、何かが 1 桁ずれているなら、 モデルに何をさせようとしているのかを再考してください。たとえば、太陽電池で \(J_{sc}\) をどうしても合わせられない場合、材料が単に十分な数の光子を吸収できておらず、 望む \(J_{sc}\) 値に達していない可能性はないでしょうか?
- 異なるデータセットは異なる種類の情報を与えます。たとえば、太陽電池の dark JV 曲線は シャント抵抗、直列抵抗、およびいくつかの移動度/再結合の詳細についての洞察を与えます。一方で light JV 曲線は、 シャント抵抗についてほとんど情報を与えないため、 \(R_{shunt}\) の正確な推定を与えることは期待しないでください。 フィットしたパラメータを解釈する前に、常に自分のデータがどのような情報を含んでいるかを考えてください。
- フィッティングプロセスは次のように動作します: 1) シミュレーションを実行する; 2) 数値結果と 実験結果の差を計算する; 3) パラメータを微調整する; 4) シミュレーションを再実行し、誤差が減少するか確認する; 5) 誤差が減少した場合、そのパラメータ変更は受理され、処理が繰り返される。これは数百から数千 回の反復を要する可能性があります。したがって、個々のシミュレーションは高速に実行されなければなりません。たとえば、 メッシュが 1000 点あるなら、フィッティングでは 10 点まで減らしてみてください。時間ステップが 1000 あるなら、100 まで減らしてください。ベースシミュレーションの すべての高速化は、フィッティングプロセス全体を高速化します。
- ディスクへのファイル書き込みは、あらゆる計算処理の中で 最も遅い部分 です。現代の SSD でさえ、 主記憶より約 30 倍遅いです (例: PC3-12800 では 456 MB/s に対して 12,800 MB/s)。USB ドライブ、ネットワークストレージ、または OneDrive/Dropbox のようなクラウドサービスを使用すると、これはさらに悪化します。高速化のためには、常に シミュレーションをローカル SSD に保存してください(ネットワークドライブや機械式ドライブではなく)。
- シミュレーションが生成するファイル数を最小限にしてください。スナップショット、光学 出力、または動的フォルダのような不要な出力をオフにしてください。適切に設定されたシミュレーションは、 約 50 ファイルしか生成しないはずです。数百見える場合は、その理由を調べてください。
- フィッティングは GUI でも行えますが、しばしば遅くなります。良い実践方法は、GUI でフィットを設定しつつ、 実行自体はコマンドラインから行うことです(手順は以下に示します)。
- フィッティングでは多数のファイルがディスクへ書き込まれるため、アンチウイルスソフトウェアが各ファイルをスキャンして 動作を遅くすることがあります。問題になる場合は、シミュレーションフォルダをリアルタイムスキャンから 除外することを検討してください。
👉 次のステップ: 次は Part B に進み、より高度なフィッティング手法を学んでください。