실험 데이터 피팅
1. 개요
어두운 JV 곡선에 다이오드 방정식을 피팅하여 ideality factor를 추출할 수 있는 것처럼, OghmaNano는 전체 장치 모델을 실험 데이터에 직접 피팅할 수 있게 해줍니다. 시뮬레이션을 측정값에 보정함으로써, 이동도, 트랩 상태 밀도, 접촉 저항, 재결합 계수와 같은 물리적으로 의미 있는 파라미터를 자기 일관적인 프레임워크 안에서 복원할 수 있습니다. 단순한 해석식과 비교하면, 물리 기반 피팅은 광학–전기적 결합을 유지하고 성능을 지배하는 메커니즘에 대해 더 풍부하고 신뢰할 수 있는 통찰을 제공합니다. 이 튜토리얼은 OghmaNano의 피팅 워크플로우를 소개하고 변수 선택, minimizer 선택, 그리고 효율적이고 재현 가능한 피팅 실행 방법을 보여줍니다.
2. 첫 번째 피팅
OghmaNano에는 모델을 실험 데이터에 피팅하는 방법을 보여주는 여러 데모 시뮬레이션이 포함되어 있습니다. 그중 하나는 간단한 드리프트–확산 모델을 예제로 사용합니다. 여기에 접근하려면 File 리본에서 New simulation 아이콘을 클릭하여 New simulation 창을 여십시오(그림 ??). 여기서 Scripting and fitting 카테고리를 더블 클릭하여 그림 ??에 표시된 폴더를 여십시오. 데모 프로젝트를 불러오려면 Fitting and parameter extraction 예제를 선택하십시오. 열리면 간단한 태양전지 시뮬레이션이 실행됩니다(그림 ??). 이 데모는 태양전지에 초점을 맞추지만, 피팅 엔진은 어떤 시뮬레이션과 실험 데이터 세트에도 적용할 수 있습니다.
새 시뮬레이션을 저장하면 주 시뮬레이션 창이 나타납니다(??). 여기서 Automation 리본(빨간색으로 강조됨)으로 이동한 다음 Fit to experiment 아이콘을 선택하여 피팅 창에 접근하십시오 ??.
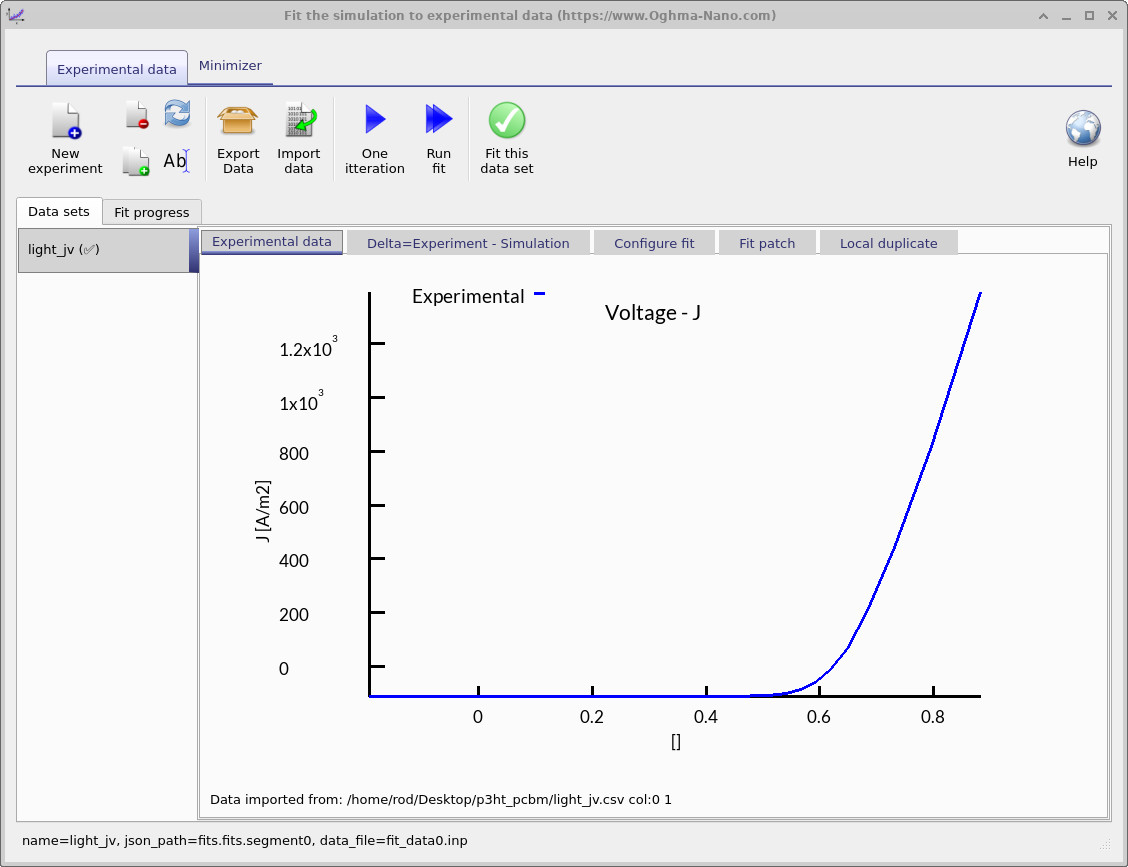
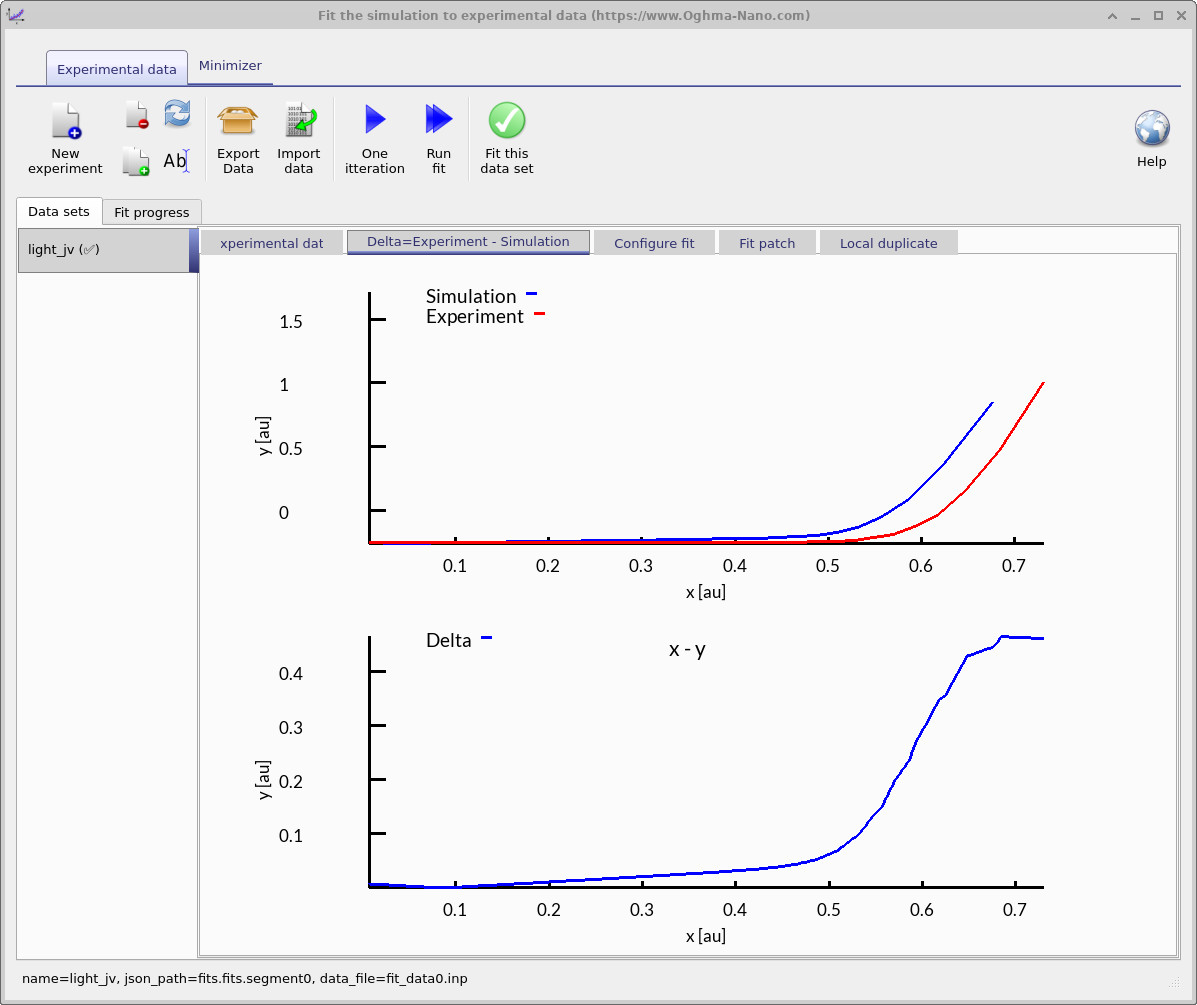
피팅 창은 최적화가 수행되는 방식을 제어합니다. 어떤 실험 데이터 세트를 사용할지, 그리고 어떤 시뮬레이션 변수를 조정할지를 지정합니다. 여기와 같이 단일 데이터 세트에 피팅할 수도 있고, 더 제약된 파라미터 추출을 위해 여러 데이터 세트에 동시에 피팅할 수도 있습니다. 그림 ??에서, 파란 선은 피팅에 사용될 실험 JV 곡선을 나타냅니다.
💡 실습: 피팅 창 사용하기
- 작업 1 – 한 번 반복: One iteration 버튼을 클릭하여 피팅 보기를 갱신하십시오 (??a). Delta = Experiment − Simulation 탭에서는 시뮬레이션된 JV(파란색)가 실험 JV(빨간색) 위에 겹쳐 표시되고, 점별로 정의된 녹색 delta 곡선도 보게 됩니다 \( \Delta(V) = J_{\mathrm{exp}}(V) - J_{\mathrm{sim}}(V) \). 좋은 시작점은 녹색 곡선이 전압 범위 전체에서 0에 가깝게 있는 경우입니다.
-
작업 2 – 피팅 실행:
자동 minimizer를 실행하려면 Run fit을 누르십시오(다시 누르면 실행이 중지됩니다).
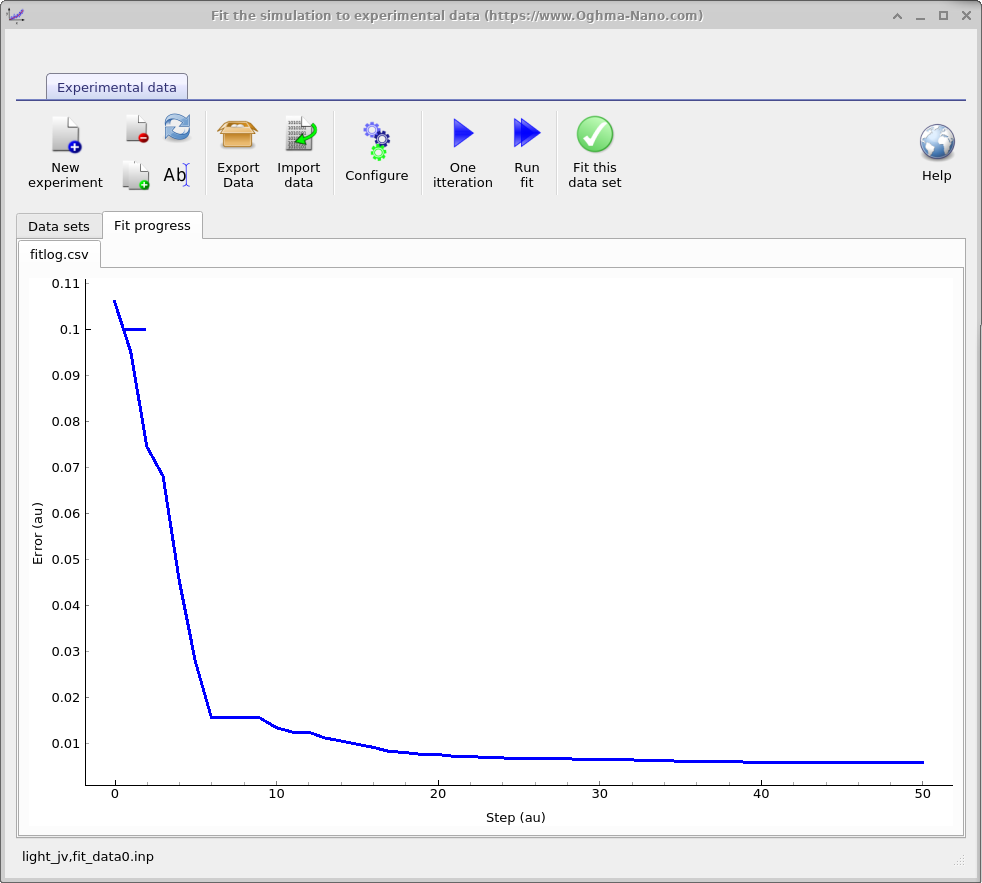
처음 몇 단계 동안은 오차가 잠시 증가할 수 있지만, 시뮬레이션 곡선과
실험 곡선이 수렴하면서 이후에는 감소해야 합니다. Fit progress 탭으로 전환하여
반복에 따른 오차를 플로팅하십시오
(??b); 이 그래프는 또한
외부 플로팅을 위해 시뮬레이션 디렉터리의
fitlog.csv에 저장됩니다. 일반적인 설정에서는 이 단계에 약 30 초가 걸립니다.
3. 데이터 추가 및 제거
메인 피팅 창은 실험 데이터를 추가, 관리, 피팅하는 방식을 제어하는 도구 모음을 제공합니다. 이러한 버튼을 통해 데이터 세트를 가져오거나 제거하고, 어떤 파라미터를 변화시킬지 구성하며, 피팅 과정을 시작하거나 중지할 수 있습니다. 가장 중요한 옵션은 다음과 같습니다:
- New experiment: 피팅 창에 또 다른 실험 데이터 세트를 추가합니다. 예를 들어, 광 JV 곡선과 어두운 JV 곡선을 모두 포함할 수 있습니다. 여러 데이터 세트에 대해 피팅하면 추출된 파라미터의 신뢰성이 향상되지만, 피팅 과정은 더 느려지고 더 어려워집니다.
- Delete experiment: 선택한 데이터 세트를 피팅에서 제거합니다.
- Clone experiment: 현재 데이터 세트의 복사본을 만듭니다.
- Rename experiment: 선택한 데이터 세트의 이름을 바꿀 수 있습니다.
- Export data: 현재 피팅과 데이터를 압축된 zip 파일로 저장합니다.
- Import data: 외부 실험 데이터를 피팅 창으로 불러옵니다(자세한 내용은 Import Wizard 섹션 참조).
- Configure: 피팅 중 조정할 변수를 정의하는 설정 창을 엽니다(아래에서 자세히 설명).
- One iteration: 단일 피팅 스텝을 실행하여 시뮬레이션이 실험 데이터에 얼마나 가까운지 확인합니다. 자동 피팅을 실행하기 전에 이 옵션을 사용하고 파라미터를 수동으로 조정하여 합리적인 시작점을 얻는 것이 권장됩니다.
- Run fit: 자동 피팅 알고리즘을 시작합니다. 다시 버튼을 눌러 수동으로 중지할 때까지 계속 진행됩니다.
- Fit this data set: 현재 선택된 데이터 세트에 대한 피팅을 활성화하거나 비활성화합니다.
4. Minimizer 리본
Minimizer 리본은 피팅 중 사용되는 최적화 알고리즘을 제어합니다. 이 탭에서 적용할 minimizer(예: 기본값인 Nelder–Mead downhill simplex)를 선택하고 그 설정을 구성할 수 있습니다. 리본에는 피팅 변수 관리, 파라미터 복제, 그리고 피팅을 제한하는 수학적 규칙 적용을 위한 도구도 포함되어 있습니다. 이러한 옵션을 조정하면 알고리즘이 파라미터 공간을 탐색하는 방식을 제어하고, 속도와 정확도의 균형을 맞추며, 피팅 과정에서 물리적으로 의미 있는 제약 조건이 강제되도록 할 수 있습니다.
5. 피팅할 변수 설정
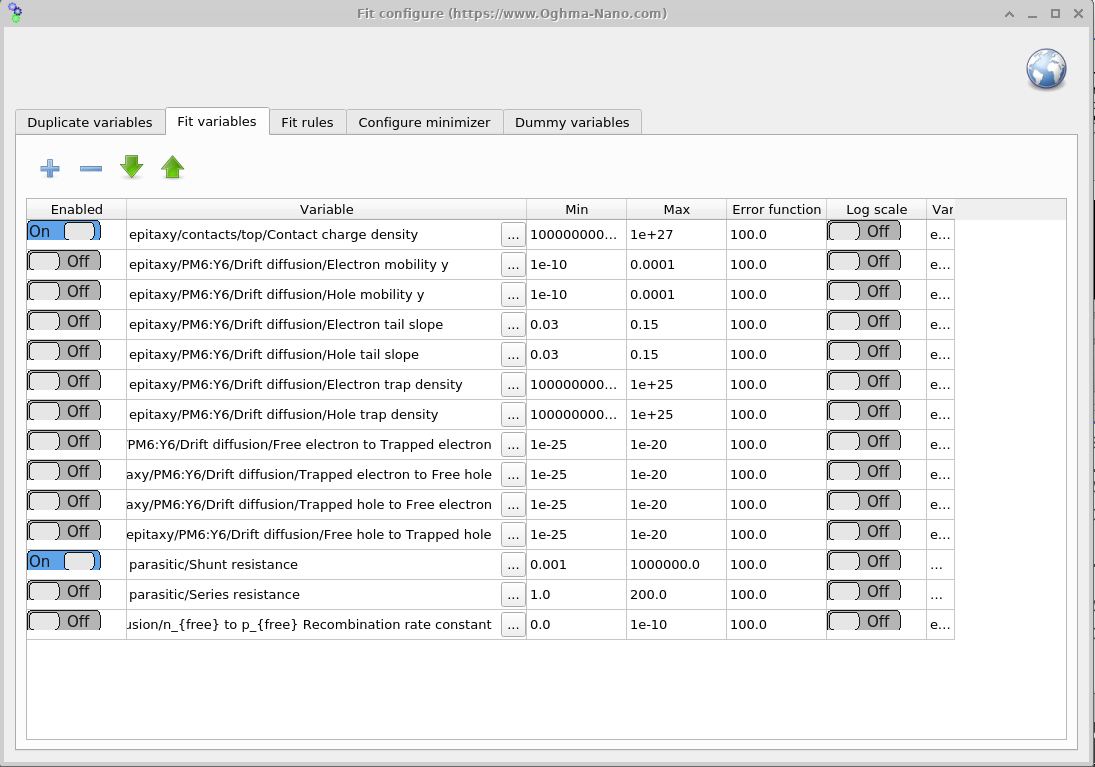
Fit variables 창을 열려면 피팅 창의 Minimizer 리본으로 이동하여 (그림 ??) Fitting variables를 클릭하십시오. 이 패널(그림 ??)을 통해 피팅 중 어떤 파라미터를 변화시킬지 선택하고 경계를 설정할 수 있습니다. 속도와 견고성을 위해, 처음에는 대칭적인 소수의 파라미터로 시작하십시오. 합리적인 초기 피팅을 얻은 뒤에 더 많은 변수(또는 비대칭성)를 추가하십시오.
Fit variables 표에는 일곱 개의 열이 있습니다: Enabled, Variable, Min, Max, Error function, Log scale, 그리고 Variable (JSON).
- Enabled: 변수 피팅을 켜거나 끕니다.
- Variable: 피팅할 변수의 경로를 영문으로 설명합니다.
- Min: 변수가 가질 수 있는 최소값입니다.
- Max: 변수가 가질 수 있는 최대값입니다.
- Error function: 변수가 최소–최대 범위를 벗어날 경우 전체 피팅 오차에 추가되는 패널티입니다. 이는 사실상 알고리즘을 허용된 경계 안으로 다시 밀어 넣는 역할을 합니다.
- Log scale: 로그 스케일로 파라미터를 피팅합니다. 많은 자릿수 범위에 걸친 변수를 전체 범위에서 탐색할 수 있도록 하는 데 유용합니다.
- Variable (JSON): 보통 숨겨져 있으며,
json형식에서 파라미터의 전체 경로를 나타냅니다. 백엔드는 이 경로를 사용하고, English 경로는 가독성을 위한 것이며 항상 정확하지 않을 수 있습니다.
6. 변수 복제
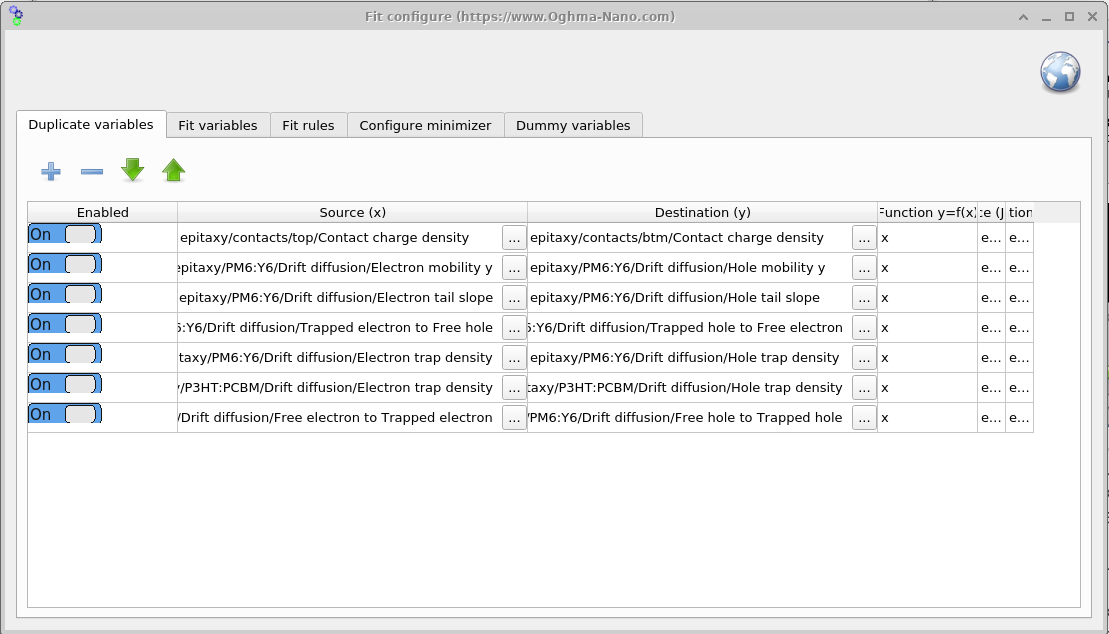
Minimizer 리본에서 Duplicate variables 창을 여십시오 (??). 이 도구는 모든 반복에서 source 파라미터를 destination 파라미터에 반영합니다. 대칭 장치 예제에서는 전자 측 파라미터만 피팅하고 Duplicate variables를 사용하여 그 값을 대응하는 정공 파라미터에 복사함으로써 피팅 내내 둘이 같게 유지합니다 ( ?? 참조).
Function y = f(x) 열은 소스 값 x가
목적지 y에 기록되기 전에 어떻게 변환되는지를 정의합니다. 기본값 x는 직접 복사를 수행하며,
2*x(값을 두 배로 함) 또는 x + 0.05(오프셋 적용)와 같은 예도 가능합니다.
7. 피팅 규칙
Minimizer 리본에서 접근하는 Fit rules 창(??)을 통해 수학적 제약 조건을 피팅 과정에 적용할 수 있습니다. 규칙은 조건이 위반될 때마다 오차 함수에 패널티를 추가합니다. 예를 들어 한 파라미터가 항상 다른 파라미터보다 커야 한다는 조건을 강제하거나, 변수가 허용 가능한 범위를 벗어날 경우 패널티를 적용할 수 있습니다. 이는 피팅이 물리적으로 의미 있게 유지되도록 돕고 minimizer가 비현실적인 파라미터 조합을 탐색하는 것을 방지합니다.
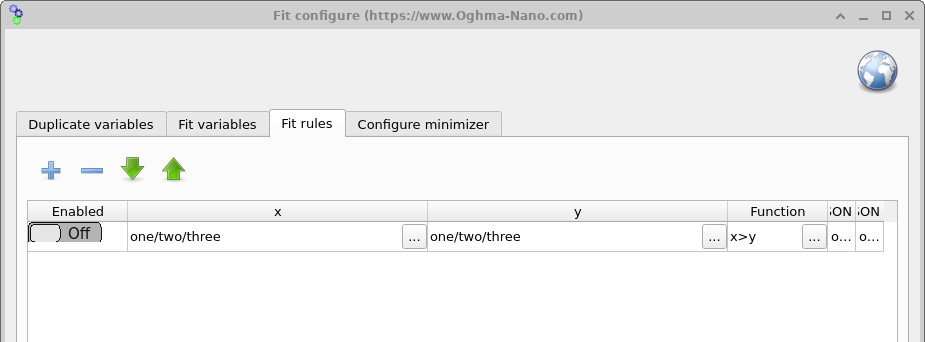
x > y와 같은 제약을 정의하여
파라미터 간 관계를 강제할 수 있습니다. 규칙이 깨지면 피팅에 추가 오차가 더해져,
minimizer가 유효한 파라미터 공간 영역으로 되돌아가도록 유도합니다.
💡 피팅을 위한 핵심 팁과 요령:
- 일반적으로 피팅은 많은 인내와 수동 미세 조정이 필요한 까다로운 과정입니다. 버튼 하나를 클릭하면 그냥 작동할 것이라고 기대하지 마십시오 — 좋은 피팅을 얻으려면 신중하게 작업해야 합니다.
- 피팅이 잘 되지 않는다면, 장치에 대해 세운 물리적 가정이 잘못되었을 수 있습니다. 모델은 물리적으로 타당한 데이터에만 피팅될 수 있으므로, 어떤 값이 한 자릿수 이상 어긋난다면 모델에 무엇을 시키고 있는지 다시 생각해 보십시오. 예를 들어 태양전지에서 \(J_{sc}\)를 도저히 맞출 수 없다면, 원하는 \(J_{sc}\) 값을 달성하기에 재료가 단순히 광자를 충분히 흡수하지 못하는 것은 아닌지 생각해 보십시오.
- 서로 다른 데이터 세트는 서로 다른 유형의 정보를 제공합니다. 예를 들어 태양전지의 어두운 JV 곡선은 병렬 저항, 직렬 저항, 일부 이동도/재결합 세부 정보에 대한 통찰을 제공합니다. 반면 광 JV 곡선은 병렬 저항에 대한 정보를 거의 제공하지 않으므로, \(R_{shunt}\)에 대한 정확한 추정치를 제공할 것이라고 기대하지 마십시오. 피팅된 파라미터를 해석하기 전에 데이터에 어떤 정보가 포함되어 있는지 항상 생각하십시오.
- 피팅 과정은 다음과 같이 작동합니다: 1) 시뮬레이션 실행; 2) 수치 결과와 실험 결과의 차이 계산; 3) 파라미터 조정; 4) 시뮬레이션을 다시 실행하고 오차가 줄어드는지 확인; 5) 오차가 줄어들면 파라미터 변화가 स्वीकार되고 과정이 반복됨. 이는 수백 또는 수천 번의 반복이 걸릴 수 있습니다. 따라서 개별 시뮬레이션은 빠르게 실행되어야 합니다. 예를 들어 메시가 1000 포인트라면 피팅을 위해 10으로 줄여보십시오. 시간 스텝이 1000개라면 100으로 줄이십시오. 기본 시뮬레이션의 모든 속도 향상은 피팅 과정을 가속합니다.
- 디스크에 파일을 쓰는 것은 모든 계산 과정에서 가장 느린 부분입니다. 최신 SSD조차도 주 메모리보다 약 30배 느립니다 (예: PC3-12800에서 456 MB/s 대 12,800 MB/s). USB 드라이브, 네트워크 저장소 또는 OneDrive/Dropbox 같은 클라우드 서비스를 사용하면 이는 더 악화됩니다. 속도를 위해서는 항상 시뮬레이션을 로컬 SSD에 저장하십시오(네트워크나 기계식 드라이브가 아님).
- 시뮬레이션이 생성하는 파일 수를 최소화하십시오. 스냅샷, 광학 출력 또는 동적 폴더와 같은 불필요한 출력을 끄십시오. 잘 구성된 시뮬레이션은 약 50개의 파일만 생성해야 합니다. 수백 개가 보인다면, 그 이유를 조사하십시오.
- GUI에서 피팅을 수행할 수도 있지만, 종종 느립니다. 좋은 방법은 GUI에서 피팅을 설정하되 명령줄에서 실행하는 것입니다(지침은 아래에 제공됩니다).
- 피팅은 디스크에 많은 파일을 쓰기 때문에, 안티바이러스 소프트웨어가 각 파일을 검사하면서 속도를 저하시킬 수 있습니다. 이것이 문제가 된다면 실시간 검사에서 시뮬레이션 폴더를 제외하는 것을 고려하십시오.
👉 다음 단계: 이제 Part B로 계속 진행하여 더 고급 피팅 방법을 살펴보십시오.