تولید مجموعهدادههای یادگیری ماشین
این فصل توضیح میدهد که چگونه با استفاده از OghmaNano مجموعهدادههای یادگیری ماشین تولید کنید. معمولاً این مجموعهدادهها صادر شده و با استفاده از چارچوبهای خارجی مانند TensorFlow برای آموزش، استنتاج، یا پیشبینی پردازش میشوند.
1. مقدمه
اغلب مطلوب است که پارامترهای فیزیکی دستگاه از دادههای تجربی با استفاده از مدلسازی استخراج شوند. برای مثال، ممکن است مجموعهای از منحنیهای JV در اختیار داشته باشید و بخواهید تحرک حامل بار و نرخ بازترکیب دستگاه را تعیین کنید. بهصورت سنتی، این کار با برازش یک مدل مبتنی بر فیزیک، مانند OghmaNano، به دادهها انجام میشود (همانطور که در آموزش برازش توضیح داده شده است). نقطهضعف این رویکرد این است که برازش یک مجموعهداده منفرد میتواند زمانبر باشد، و وقتی چندین مجموعهداده باید تحلیل شوند دشواری آن بهطور قابلتوجهی افزایش مییابد. فرایند برازش پیچیده است و معمولاً به تخصص قابلتوجهی در شبیهسازی عددی و مقدار زیادی مداخله دستی نیاز دارد. در نتیجه، برازش دقیق دستگاه فقط توسط زیرمجموعه نسبتاً کوچکی از جامعه انجام میشود.
یک رویکرد مدرنتر استفاده از یادگیری ماشین است. بهجای برازش مستقیم یک منحنی JV منفرد، ابتدا یک شبیهسازی ساخته میشود که نماینده ساختار دستگاه است. بهجای بهینهسازی پارامترهای الکتریکی منفرد، هزاران نسخه از این دستگاه با مقادیر پارامتر بهصورت تصادفی انتخابشده تولید میشوند. هر یک از این نمونهها بهعنوان یک دستگاه مجازی شناخته میشود. سپس از یک برنامه شبیهسازی مانند OghmaNano برای تولید منحنیهای JV برای هر دستگاه مجازی استفاده میشود، و مجموعهدادهای متشکل از منحنیهای JV جفتشده با پارامترهای الکتریکی متناظر آنها تولید میشود. از این دادهها میتوان برای آموزش یک مدل یادگیری ماشین جهت پیشبینی مستقیم پارامترهای الکتریکی از روی مشخصههای JV استفاده کرد. در این چارچوب، OghmaNano بهعنوان یک تبدیل مستقیم عمل میکند و پارامترهای الکتریکی را به دادههای تجربی شبیهسازیشده نگاشت میکند، در حالی که مدل یادگیری ماشین تبدیل معکوس را فراهم میکند. پس از آموزش، مدل را میتوان برای استخراج پارامترهای ماده از دستگاههای واقعی به کار برد.
مزیت کلیدی این رویکرد آن است که پس از آموزش، مدل یادگیری ماشین میتواند پارامترهای ماده را در عرض چند ثانیه از دادههای تجربی استخراج کند، بدون آنکه لازم باشد کاربر در شبیهسازی عددی متخصص باشد. با این حال، موفقیت این روش بهطور بحرانی به تولید یک مجموعهداده آموزشی بزرگ و باکیفیت وابسته است. فرایند ساخت چنین مجموعهدادههایی با استفاده از OghmaNano در صفحات بعدی توضیح داده شده است.
2. باز کردن مثال
مثالی که در این صفحه بررسی میشود از طریق دکمه شبیهسازی جدید در پنجره اصلی قابل دسترسی است. این کار مرورگر شبیهسازی جدید را که در ?? نشان داده شده است باز میکند.
از فهرست دستههای شبیهسازی موجود، روی یادگیری ماشین دوبار کلیک کنید تا مثالهای یادگیری ماشین نمایش داده شوند (??). با انتخاب مثال ML مربوط به PM6:Y6 یک شبیهسازی از پیش پیکربندیشده متناظر با دستگاه و گردشکاری که در این فصل بررسی میشود بارگذاری میشود.
پس از باز شدن، شبیهسازی همان ساختار دستگاه و تنظیمات خودکارسازی استفادهشده در سراسر این بخش را ارائه میکند و میتوان از آن مستقیماً برای تولید داده آموزشی یادگیری ماشین بدون پیکربندی بیشتر استفاده کرد.
3. تعریف شبیهسازیها و بردارهای خروجی
پس از آنکه شبیهسازی مثال باز شد، پنجره اصلی شبیهسازی که در شکل ?? نشان داده شده است به شما نمایش داده میشود. این پنجره ساختار دستگاه کاملاً پیکربندیشدهای را که در سراسر این فصل استفاده میشود نشان میدهد. در ریبون Automation، یک آیکون Machine learning دیده میشود که با یک نماد دایرهای آبی نمایش داده شده است. با کلیک روی این آیکون، پنجره اصلی کنترل یادگیری ماشین که در شکل ?? نشان داده شده است باز میشود. از این پنجره، تولید داده آموزشی یادگیری ماشین پیکربندی و اجرا میشود.
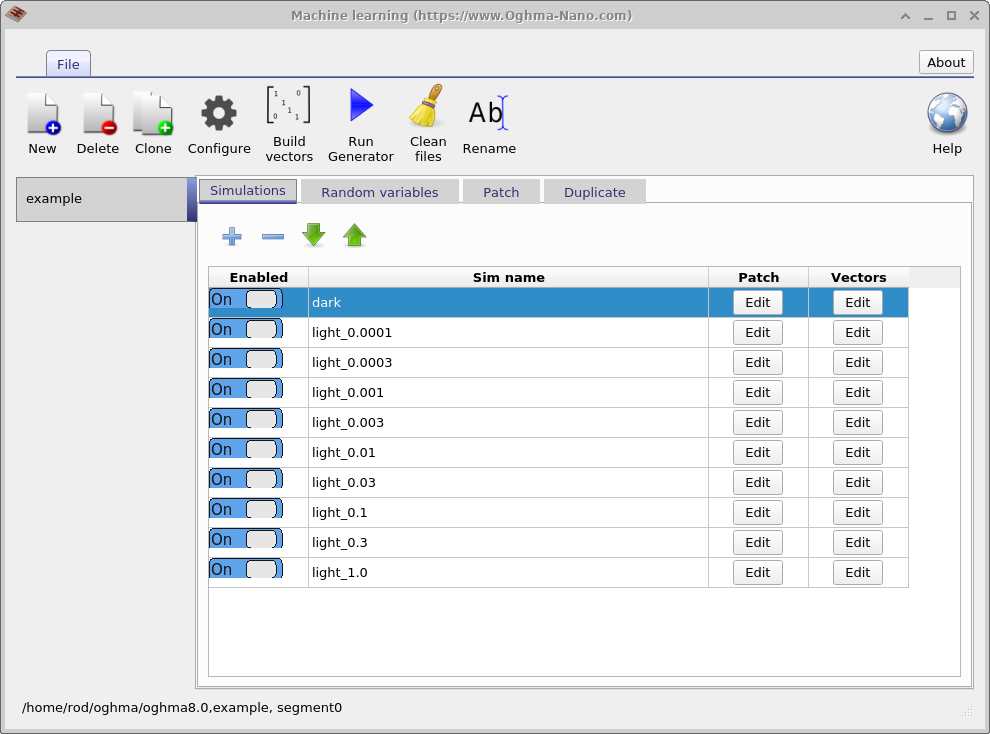
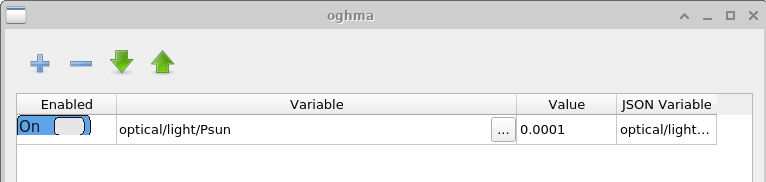
هدف اصلی این پنجره تولید مجموعهدادههای بزرگ برای آموزش الگوریتمهای یادگیری ماشین است. مجموعهدادهای که در این مثال تولید میشود example نام دارد. اولین تب نمایشدادهشده تب Simulations است که مجموعه شبیهسازیهای انجامشده برای هر دستگاه مجازی را تعریف میکند. در اینجا، یک منحنی JV تاریک و نه منحنی JV روشنشده شبیهسازی میشوند، با شدتهای نوری در بازه از 0.0001 Suns تا 1.0 Suns. شبیهسازیهای منفرد را میتوان با استفاده از کلید Enabled فعال یا غیرفعال کرد. اگر در ستون Patch برای ورودی \(light\_0.0001\) روی دکمه Edit کلیک شود، پنجره Patch نشاندادهشده در ?? باز میشود.
هدف پنجره Patch اصلاح پارامترها درون یک شبیهسازی مجازی است. در این مثال، چندین منحنی JV تحت شرایط روشنایی متفاوت با استفاده از یک ساختار دستگاه پایه یکسان تولید میشوند. برای دستیابی به این هدف، شدت نور باید برای هر شبیهسازی بهطور مستقل تنظیم شود. باز کردن پنجره patch برای \(light\_0.0001\) نشان میدهد که پارامتر شبیهسازی optical/light/Psun که شدت روشنایی را کنترل میکند، روی \(0.0001\) تنظیم شده است. برای شبیهسازی dark، همین پارامتر روی \(0.0\) تنظیم شده است. به این ترتیب، چندین شرط تجربی را میتوان بهطور سازگار با استفاده از یک شبیهسازی پایه واحد شبیهسازی کرد.
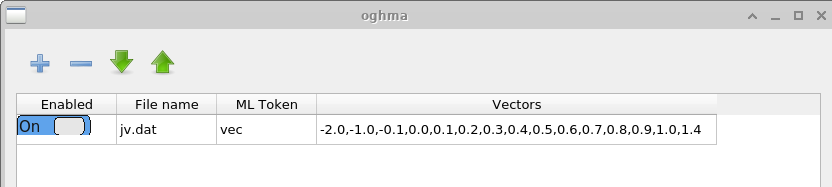
پنجره Vectors مشخص میکند کدام دادهها از شبیهسازیهای تکمیلشده استخراج شوند تا بردارهای ورودی یادگیری ماشین را تشکیل دهند. در این مثال، نقاط داده بین −2.0 V و 1.4 V از فایل \(jv.dat\) استخراج میشوند، که شامل مشخصههای شبیهسازیشده جریان–ولتاژ است. برای شبیهسازیهای حوزه زمان، کاربر ممکن است در عوض دادهها را از فایلهایی مانند \(time\_i.csv\) یا هر فایل خروجی مناسب دیگر استخراج کند. تعداد نقاط استفادهشده برای ساخت هر بردار ورودی توسط کاربر انتخاب میشود. بردارهای بلندتر هزینه محاسباتی آموزش را افزایش میدهند اما ممکن است ویژگیهای دقیقتری از منحنی JV را ثبت کنند.
4. تعریف متغیرهای تصادفی
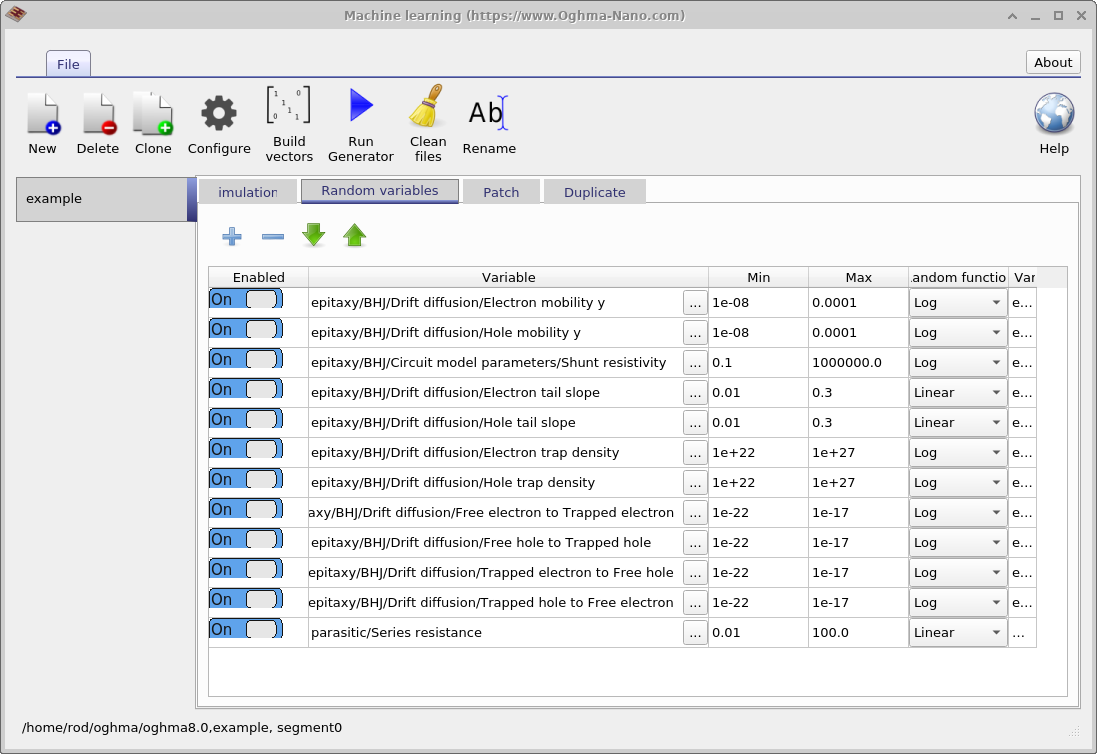
گام بعدی تعریف این است که کدام پارامترهای مدل باید تصادفیسازی شوند. این کار با استفاده از تب Random variables در پنجره اصلی یادگیری ماشین انجام میشود. جدول شامل پنج ستون است. ستون Enabled تعیین میکند که آیا یک پارامتر در فرایند تصادفیسازی گنجانده میشود یا نه. ستون Variable مشخص میکند کدام پارامتر شبیهسازی تغییر میکند. ستونهای Min و Max کرانهای پایین و بالای بازه پارامتر را تعریف میکنند، و ستون Random function مشخص میکند که مقادیر از یک توزیع خطی یا لگاریتمی برداشته شوند.
توزیعهای لگاریتمی برای پارامترهایی که چندین مرتبه بزرگی را پوشش میدهند توصیه میشوند، در حالی که توزیعهای خطی برای پارامترهایی مناسباند که در بازه نسبتاً محدودی تغییر میکنند. استفاده از یک توزیع لگاریتمی تضمین میکند که مقادیر هنگام مشاهده روی مقیاس لگاریتمی بهطور یکنواخت نمونهبرداری شوند، بهجای آنکه به سمت انتهای بالایی بازه خوشهبندی شوند. برای مثال، یک پارامتر خطی مناسب انرژی اورباخ است، که معمولاً بین 30 و 150 meV تغییر میکند. در مقابل، چگالیهای تله برای نمونهبرداری لگاریتمی کاملاً مناسب هستند، زیرا ممکن است از \(1 \times 10^{15}\,\mathrm{m^{-3}}\) تا \(1 \times 10^{25}\,\mathrm{m^{-3}}\) تغییر کنند.
5. تعریف تعداد شبیهسازیها
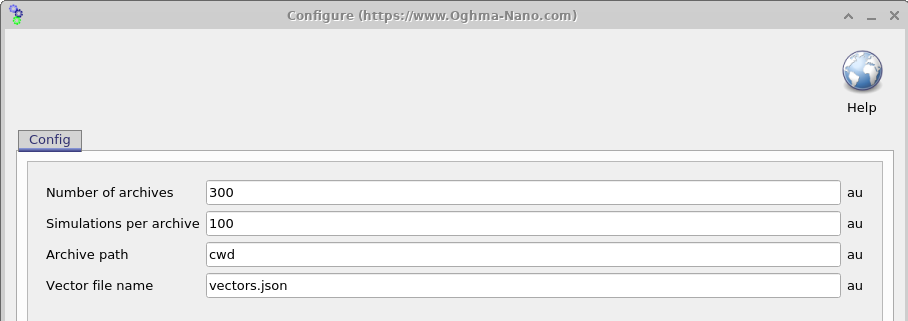
وقتی شبیهسازی پیکربندی شد، گام بعدی تعیین این است که چند دستگاه مجازی با پارامترهای تصادفیسازیشده باید تولید شوند. باز کردن پنجره Settings (نگاه کنید به 18.6) اجازه میدهد این موضوع با استفاده از دو پارامتر کنترل شود: Simulations per archive (\(N_{\mathrm{sim}}\)) و Number of archives (\(N_{\mathrm{arc}}\)). تعداد کل دستگاههای مجازی تولیدشده برابر است با \(N_{\mathrm{sim}} \times N_{\mathrm{arc}}\).
نتایج شبیهسازی در فایلهای ZIP که آرشیو نامیده میشوند نوشته میشود، بهطوری که هر آرشیو شامل \(N_{\mathrm{sim}}\) دستگاه مجازی است. در مثال نشاندادهشده در اینجا، \(N_{\mathrm{sim}} \times N_{\mathrm{arc}} = 3000\) دستگاه مجازی تولید شده و در 100 فایل آرشیو ذخیره میشوند. توجه به این نکته مهم است که در این مثال، هر دستگاه مجازی از یک شبیهسازی JV تاریک و نه شبیهسازی JV روشنشده تشکیل شده است. در نتیجه، تعداد کل فایلهای خروجی میتواند بهسرعت افزایش یابد.
برای مدیریت این موضوع، تولید داده بهصورت دستهای انجام میشود. یک گروه از \(N_{\mathrm{sim}}\) شبیهسازی توسط OghmaNano تولید و اجرا میشود، سپس در یک آرشیو واحد نوشته میشود، و این فرایند تا زمانی که \(N_{\mathrm{arc}}\) آرشیو تولید شود تکرار میگردد. این رویکرد اگر فرایند متوقف شود، اتلاف داده را به آرشیوی که در حال حاضر تولید میشود محدود میکند، و همچنین انتقال فایل را سادهتر کرده و پایداری در برابر خرابی را بهبود میدهد. اجرای شبیهسازی در تمام هستههای CPU موجود بهصورت موازی انجام میشود، در حالی که ایجاد آرشیو روی یک هسته منفرد انجام میگیرد.
6. اجرای مولد مجموعهداده
پس از کامل شدن پیکربندی، با فشردن دکمه Run generator در پنجره اصلی Machine learning (18.2) فرایند تولید مجموعهداده آغاز میشود. OghmaNano سپس شروع به اجرای شبیهسازیهای تعریفشده برای هر دستگاه مجازی خواهد کرد. وقتی فرایند پایان یابد، یک پوشه با نام example در پوشه شبیهسازی ظاهر میشود، همانطور که در سمت چپ 18.8 نشان داده شده است. برای مقاصد این مثال، Simulations per archive روی 10 تنظیم شد و Number of archives روی 3 تنظیم شد تا زمان اجرا کاهش یابد.
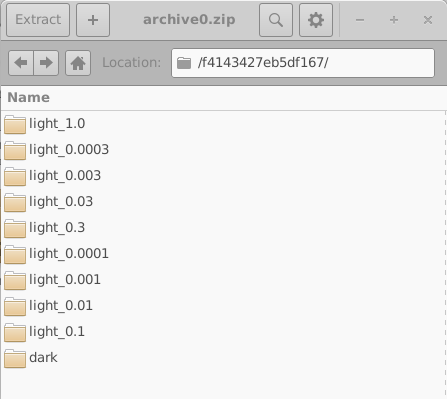
هر خطایی که در طول شبیهسازی رخ دهد در فایل errors.dat نوشته میشود. باز کردن archive0.zip ساختار داخلی یک آرشیو را که در سمت راست 18.8 نشان داده شده است آشکار میکند. هر آرشیو شامل مجموعهای از پوشهها است که هرکدام متناظر با یک دستگاه مجازی منفرد هستند.
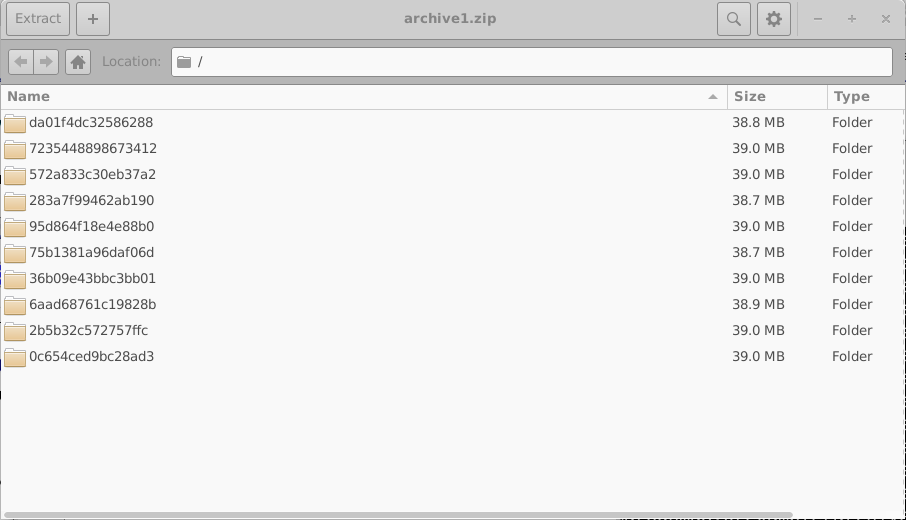
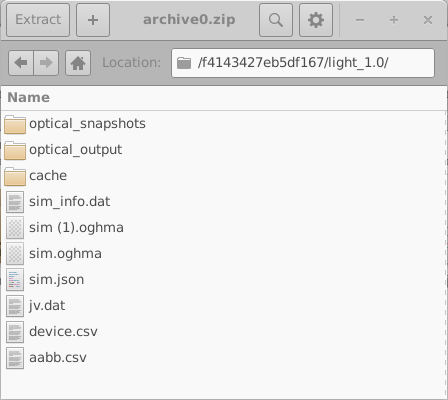
این پوشهها با استفاده از شناسههای شانزدههشتی 16 رقمی تصادفی نامگذاری شدهاند. هر پوشه شامل مجموعه کامل شبیهسازیها برای یک دستگاه مجازی است؛ در این مثال، یک شبیهسازی JV تاریک و نه شبیهسازی JV روشنشده. محتویات یکی از این پوشهها در سمت چپ 18.10 نشان داده شده است. باز کردن یک پوشه شبیهسازی منفرد (18.10، راست) یک شبیهسازی کامل OghmaNano را آشکار میکند، شامل فایل sim.json و فایل jv.dat که شامل مشخصههای جریان–ولتاژ شبیهسازیشده است. دادههای اضافی، مانند خروجیهای نوری و فایلهای cache، نیز ممکن است وجود داشته باشند.
هنگام تولید مجموعهدادههای بزرگ یادگیری ماشین، بهشدت توصیه میشود خروجی غیرضروری به حداقل برسد، زیرا مصرف کل دیسک میتواند بهسرعت افزایش یابد. این کار را میتوان با پیکربندی شبیهسازی برای تولید فقط دادههای خروجی ضروری انجام داد. تولید مجموعهداده بهصورت دستهای انجام میشود، بهطوری که شبیهسازیها بهصورت موازی روی تمام هستههای CPU موجود اجرا میشوند، در حالی که ساخت آرشیو روی یک هسته منفرد انجام میشود.
در این مثال نمایشی، فقط سه آرشیو تولید میشود. با این حال، در یک اجرای تولیدی معمول، رایج است که در حدود 200 آرشیو تولید شود که هر یک تقریباً شامل 200 دستگاه مجازی هستند.
در مثال بالا ما فقط سه آرشیو داریم اما در یک اجرای شبیهسازی عادی ممکن است تا 200 آرشیو وجود داشته باشد که هر کدام 200 شبیهسازی در خود دارند.
7. گردآوری نتایج در یک فایل واحد
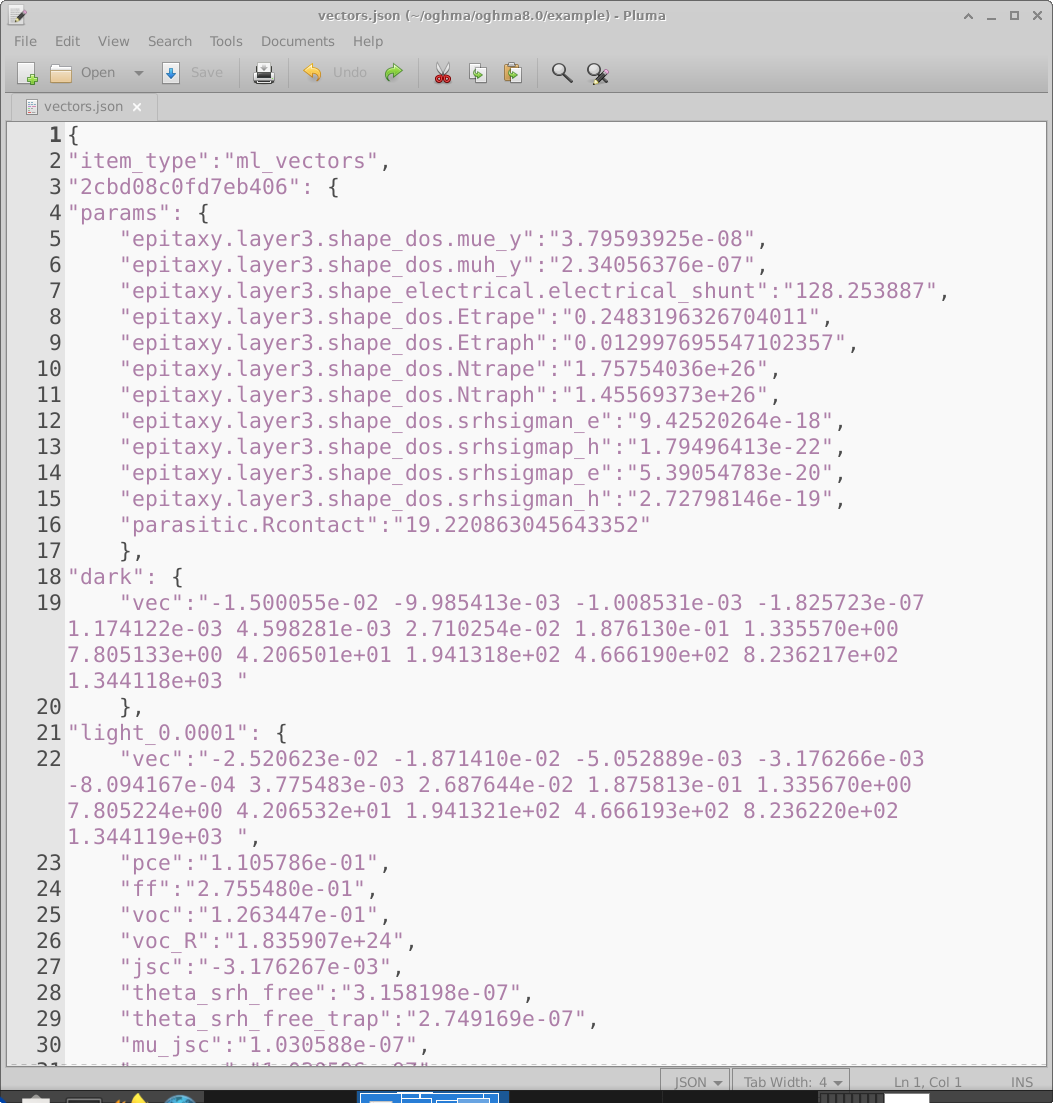
پس از تکمیل شبیهسازیها، خروجی خام OghmaNano باید به یک فایل واحد vectors تبدیل شود که برای آموزش یک مدل یادگیری ماشین مناسب باشد. با کلیک روی آیکون Build vectors در پنجره اصلی Machine learning (18.2) OghmaNano هر پوشه دستگاه مجازی را باز میکند، خروجیهای درخواستی را استخراج میکند، و آنها را در یک فایل واحد vectors.json گردآوری میکند. نمونهای از این فایل در 18.11 نشان داده شده است.
فایل بردارها یک سند JSON است که شامل تمام اطلاعات لازم برای یادگیری نظارتشده است. هر
دستگاه مجازی بهعنوان یک ورودی جداگانه ظاهر میشود. برای مثال، ورودی با برچسب
2cbd08c0fd7eb406 (خط 3) در بخش params شامل پارامترهای الکتریکی تصادفی
انتخابشده برای آن دستگاه مجازی است. پس از آن، بردارهای ورودی استخراجشده قرار میگیرند، مانند بردار JV تاریک (خط 19)
و بردار JV روشنشده در 0.0001 Suns (خط 22). واحدهای عددی در هر بردار مستقیماً از
فایل منبعی که از آن استخراج شدهاند به ارث میرسند. در این مثال بردارها از jv.dat گرفته میشوند، که
چگالی جریان را بر حسب \(A\,m^{-2}\) بهعنوان تابعی از ولتاژ ذخیره میکند، بنابراین مقادیر بردار بر حسب
\(A\,m^{-2}\) هستند. پس از بردارهای ورودی، خروجیهای اسکالر اضافی (برای مثال PCE) برای
سهولت ذخیره میشوند.
در این فایل برای هر دستگاه مجازی تولیدشده یک ورودی وجود خواهد داشت. پس از تولید vectors.json، میتوان از آن بهعنوان مجموعهداده آموزشی برای گردشکار یادگیری ماشین دلخواه شما استفاده کرد. برخی کاربران ترجیح میدهند پس از تبدیل داده به CSV آن را به TensorFlow وارد کنند؛ این کار را میتوان با استفاده از کتابخانههای استاندارد Python انجام داد.
8. از مجموعهداده تا یادگیری ماشین
بخشهای قبلی توضیح میدهند که چگونه از OghmaNano برای تولید یک مجموعهداده کامل یادگیری ماشین در قالب JSON استفاده میشود. در این مرحله، خط لوله تولید داده به پایان رسیده است: برای هر دستگاه مجازی، فایل شامل پارامترهای مدل انتخابشده بهصورت تصادفی به همراه خروجیهای شبیهسازی متناظر است که بهصورت بردارهای ورودی کدگذاری شدهاند.
گام بعدی وارد کردن این دادهها به یک چارچوب یادگیری ماشین دلخواه شما است.
در عمل، این کار معمولاً شامل خواندن فایل vectors.json و تبدیل آن به یک
قالب جدولی مانند CSV است، که سپس میتواند برای آموزش، اعتبارسنجی، و آزمون استفاده شود.
این تبدیل را میتوان بهسادگی با استفاده از ابزارهای استاندارد اسکریپتنویسی (برای مثال، Python) انجام داد.
پس از تبدیل، میتوان از دادهها برای آموزش یک شبکه عصبی یا مدل رگرسیون دیگر که با استفاده از یک چارچوب یادگیری ماشین مانند TensorFlow، PyTorch، یا کتابخانهای مشابه پیادهسازی شده است استفاده کرد. از این نقطه به بعد، انتخاب معماری شبکه، تابع هزینه، و راهبرد آموزش وابسته به کاربرد است و مستقل از OghmaNano است.
به این ترتیب، OghmaNano یک خط لوله کامل و خودکار برای تولید داده آموزشی از نظر فیزیکی سازگار فراهم میکند، در حالی که توسعه و بهینهسازی بعدی مدل یادگیری ماشین را کاملاً تحت کنترل کاربر باقی میگذارد.