機械学習データセットの生成
この章では、OghmaNano を使用して機械学習データセットを生成する方法について説明します。 通常、これらのデータセットは学習、推論、または予測のために、 TensorFlow のような外部フレームワークを使用してエクスポートおよび処理されます。
1. はじめに
モデリングを用いて実験データから物理デバイスパラメータを抽出したい場合がよくあります。 例えば、ある一連の JV 曲線があり、デバイスの電荷キャリア移動度 および再結合速度を決定したい場合です。 従来、これは OghmaNano のような物理ベースモデルをデータにフィットさせることで達成されます ( フィッティングチュートリアル で説明されているとおりです)。 この手法の欠点は、単一のデータセットのフィッティングでも時間がかかること、そして 複数のデータセットを解析しなければならない場合に難易度が大幅に増すことです。 フィッティング過程は複雑であり、通常は数値シミュレーションに関する高度な専門知識と、 かなりの手動介入を必要とします。 その結果、詳細なデバイスフィッティングを行うのはコミュニティの比較的小さな一部に限られています。
より現代的なアプローチは機械学習を使用することです。 単一の JV 曲線を直接フィットする代わりに、まずデバイス構造を表す シミュレーションを構築します。 個々の電気パラメータを最適化する代わりに、このデバイスの何千ものコピーを ランダムに選択したパラメータ値で生成します。 これらの各インスタンスは 仮想デバイス と呼ばれます。 その後、OghmaNano のようなシミュレーションプログラムを用いて、各仮想デバイスの JV 曲線を生成し、 JV 曲線とそれに対応する電気パラメータの組から成るデータセットを作成します。 このデータを用いて、JV 特性から直接電気パラメータを予測する 機械学習モデルを学習させることができます。 この枠組みにおいて、OghmaNano は電気パラメータをシミュレートされた 実験データへ写像する順変換として機能し、機械学習モデルは逆変換を提供します。 いったん学習されれば、このモデルは実デバイスから材料パラメータを抽出するために利用できます。
このアプローチの主な利点は、いったん学習されると、機械学習モデルが実験データから 材料パラメータを数秒以内で抽出でき、 ユーザーが数値シミュレーションの専門家である必要がないことです。 しかし、この手法の成功は、大規模で高品質な 学習データセットの生成に決定的に依存します。 OghmaNano を用いてそのようなデータセットを構築する過程を、以下のページで説明します。
2. 例を開く
このページで説明する例には、メイン ウィンドウの New simulation ボタンからアクセスできます。これにより、 ?? に示す New simulation ブラウザが開きます。
利用可能なシミュレーションカテゴリ一覧から、Machine learning をダブルクリックして 機械学習の例を表示します (??)。 PM6:Y6 ML example を選択すると、この章で説明するデバイス およびワークフローに対応した事前設定済みシミュレーションが読み込まれます。
開くと、このシミュレーションは本節全体で用いる同一のデバイス構造と自動化設定を表示し、 追加設定なしで機械学習用学習データの生成に直接使用できます。
3. シミュレーションと出力ベクトルの定義
例のシミュレーションを開くと、 Figure ?? に示すメインシミュレーションウィンドウが表示されます。 このウィンドウには、本章を通して使用する完全に設定済みのデバイス構造が表示されます。 Automation リボンには青い円形記号で表された Machine learning アイコンが表示されています。このアイコンを クリックすると、Figure ?? に示すメインの機械学習制御ウィンドウが開きます。 このウィンドウから、機械学習学習データの生成を設定して実行します。
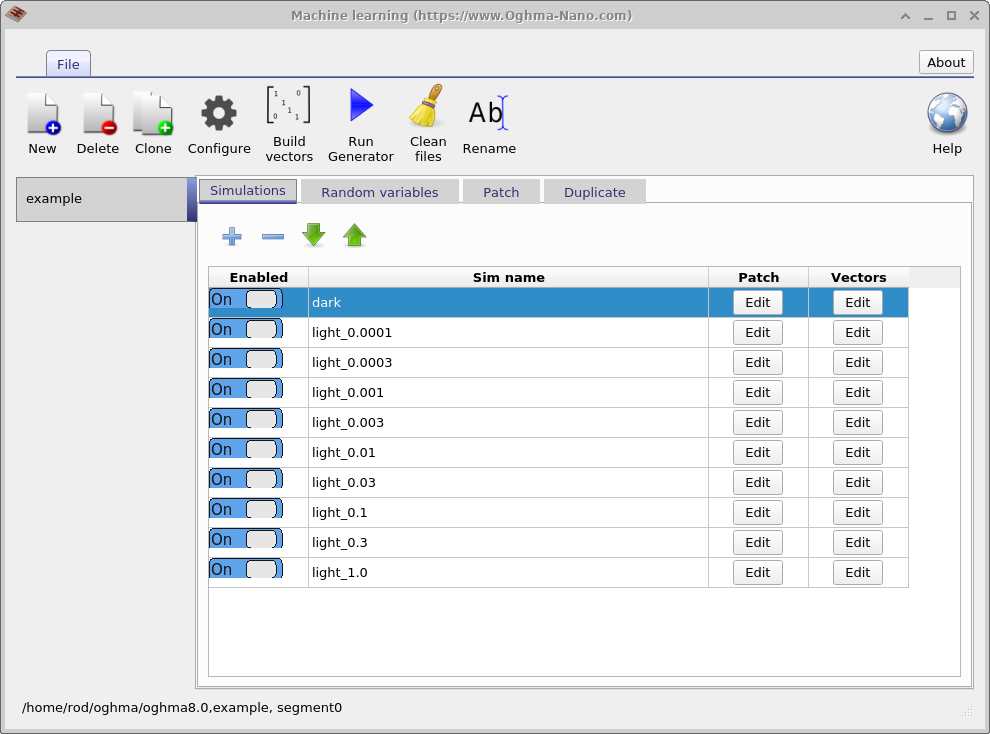
このウィンドウの主な目的は、機械学習アルゴリズムを学習させるための大規模データセットを生成することです。 この例で生成されるデータセットは example と呼ばれます。 最初に表示されるタブは Simulations タブであり、各 仮想デバイス に対して実行されるシミュレーションの集合を定義します。 この場合、暗状態 JV 曲線 1 本と、0.0001 Suns から 1.0 Suns までの光強度に対応する 9 本の照明下 JV 曲線がシミュレーションされます。 個々のシミュレーションは Enabled トグルで有効または無効にできます。 \(light\_0.0001\) の行にある Patch 列の Edit ボタンをクリックすると、 ?? に示す Patch window が開きます。
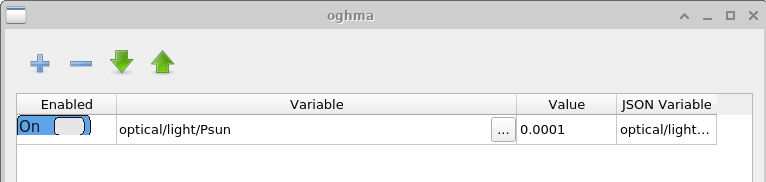
Patch window の目的は、仮想シミュレーション内のパラメータを変更することです。 この例では、同じ ベースデバイス構造を用いて異なる照明条件下の複数の JV 曲線が生成されます。 これを実現するために、各シミュレーションごとに光強度を独立に調整する必要があります。 \(light\_0.0001\) のパッチウィンドウを開くと、照明強度を制御する シミュレーションパラメータ optical/light/Psun が \(0.0001\) に設定されていることが分かります。 dark シミュレーションでは、同じパラメータが \(0.0\) に設定されています。 このようにして、単一のベース シミュレーションを用いて複数の実験条件を一貫してシミュレーションできます。
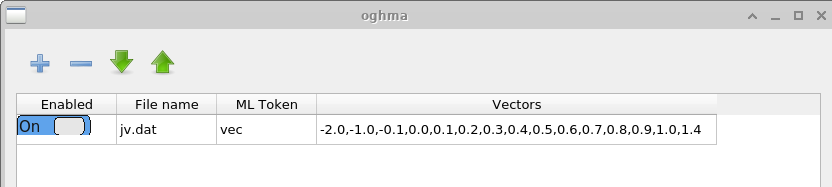
Vectors ウィンドウでは、完了したシミュレーションからどのデータを抽出して 機械学習入力ベクトルを形成するかを定義します。 この例では、シミュレートされた電流–電圧特性を含む \(jv.dat\) ファイルから、−2.0 V から 1.4 V の間のデータ点が抽出されます。 時間領域シミュレーションの場合、ユーザーは代わりに \(time\_i.csv\) や、その他の適切な出力ファイルからデータを抽出することもあります。 各入力ベクトルを構成する点数はユーザーが選択します。 ベクトルが長いほど学習の計算コストは増加しますが、JV 曲線のより詳細な特徴を捉えられる可能性があります。
4. ランダム変数の定義
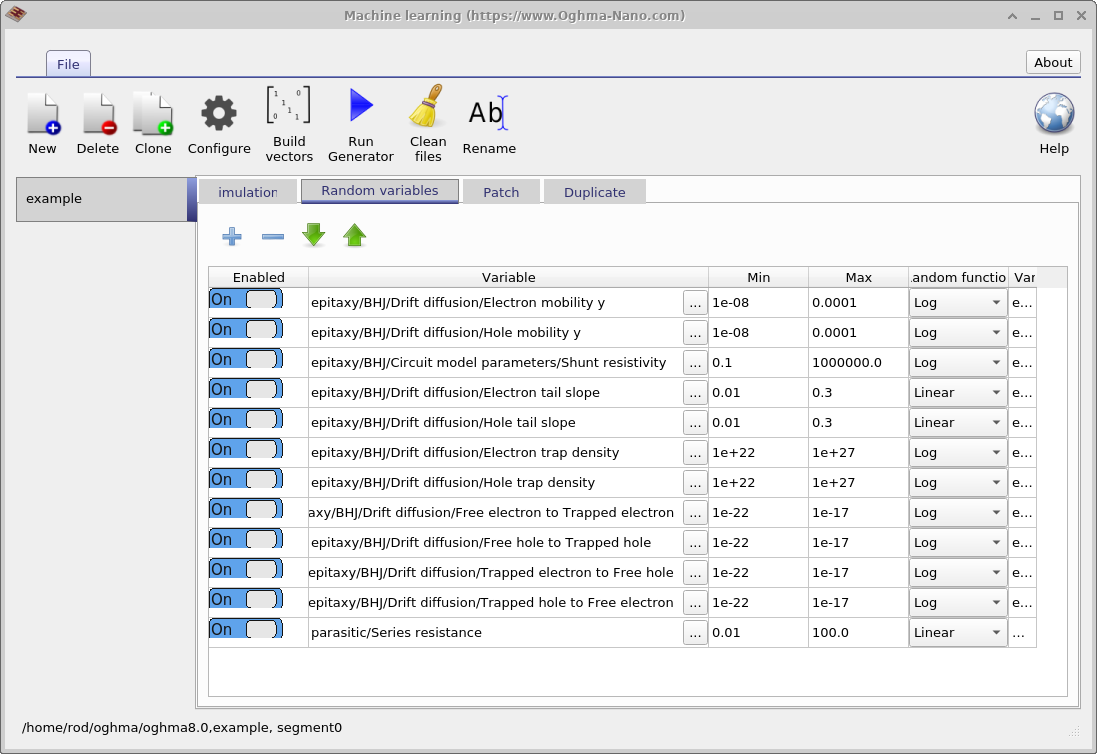
次のステップは、どのモデルパラメータをランダム化するかを定義することです。 これはメイン機械学習ウィンドウの Random variables タブで行います。 表には 5 列があります。 Enabled 列は、そのパラメータをランダム化過程に含めるかどうかを決定します。 Variable 列は、どのシミュレーションパラメータを変化させるかを指定します。 Min および Max 列はパラメータ範囲の下限と上限を定義し、 Random function 列は値が線形分布から引かれるか対数分布から引かれるかを指定します。
複数桁にわたるパラメータには対数分布が推奨され、 比較的狭い範囲で変動するパラメータには線形分布が適しています。 対数分布を用いることで、値は対数スケール上で見たときに均等にサンプリングされ、 範囲の上限側に偏って集中することがありません。 例えば、適切な線形パラメータの例として Urbach エネルギーがあり、 通常 30 から 150 meV の範囲で変動します。 これに対してトラップ密度は対数サンプリングに適しており、 \(1 \times 10^{15}\,\mathrm{m^{-3}}\) から \(1 \times 10^{25}\,\mathrm{m^{-3}}\) の範囲で変動する可能性があります。
5. シミュレーション数の定義
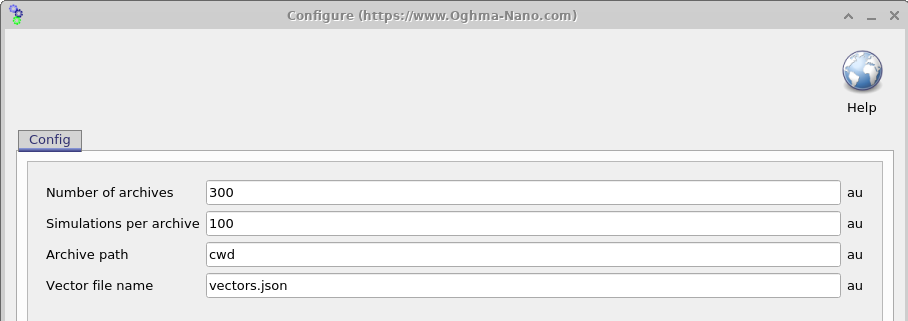
シミュレーションの設定が完了したら、次のステップは、ランダム化パラメータをもつ 仮想デバイス をいくつ生成するかを決めることです。 Settings window を開くと( 18.6 を参照)、 これを 2 つのパラメータ、 Simulations per archive(\(N_{\mathrm{sim}}\))と Number of archives(\(N_{\mathrm{arc}}\))で制御できます。 生成される仮想デバイスの総数は \(N_{\mathrm{sim}} \times N_{\mathrm{arc}}\) で与えられます。
シミュレーション結果は archives と呼ばれる ZIP ファイルに書き込まれ、各アーカイブには \(N_{\mathrm{sim}}\) 個の仮想デバイスが含まれます。 ここに示した例では、 \(N_{\mathrm{sim}} \times N_{\mathrm{arc}} = 3000\) 個の仮想デバイスが生成され、100 個のアーカイブファイルに分けて保存されます。 この例では、各仮想デバイスが 1 つの暗状態 JV シミュレーションと 9 つの照明下 JV シミュレーションから構成されていることに注意することが重要です。 その結果、総出力ファイル数は急速に増大する可能性があります。
これを管理するために、データ生成はバッチ単位で実行されます。 \(N_{\mathrm{sim}}\) 個のシミュレーション群が生成され OghmaNano によって実行され、 その後単一アーカイブに書き込まれ、この過程が \(N_{\mathrm{arc}}\) 個のアーカイブが生成されるまで繰り返されます。 この方法により、プロセスが中断した場合のデータ損失は現在生成中のアーカイブに限定され、 またファイル転送が容易になり破損に対する堅牢性も向上します。 シミュレーション実行は利用可能なすべての CPU コアにわたって並列化され、 アーカイブ作成は単一コアで実行されます。
6. データセットジェネレータの実行
設定が完了したら、メイン Machine learning ウィンドウの Run generator ボタンを押すと (18.2)、 データセット生成プロセスが開始されます。 OghmaNano はその後、各 仮想デバイス に対して定義されたシミュレーションの実行を開始します。 プロセスが終了すると、example という名前のディレクトリがシミュレーションディレクトリに現れます。 これは 18.8 の左側に示されています。 この例では、実行時間を短縮するために Simulations per archive を 10、 Number of archives を 3 に設定しています。
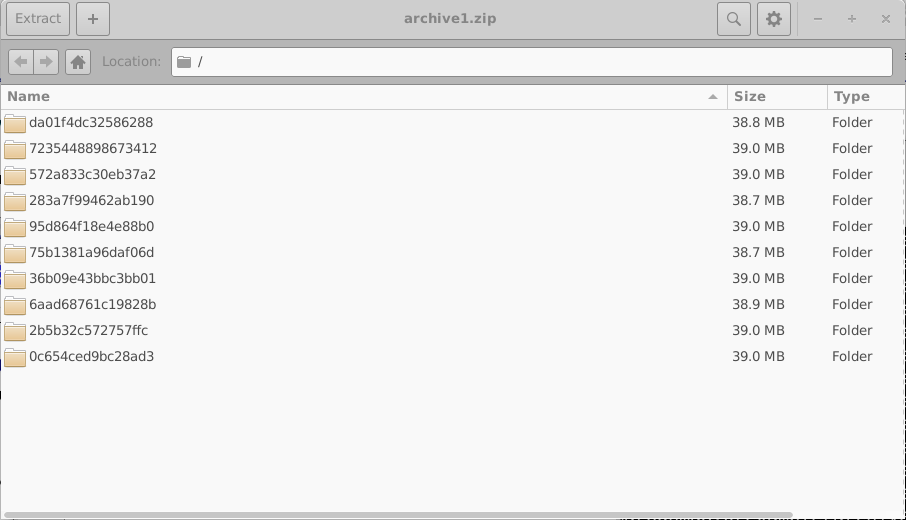
シミュレーション中に発生したすべてのエラーは errors.dat というファイルに書き込まれます。 archive0.zip を開くと、アーカイブの内部構造が 18.8 の右側に示されているように表示されます。 各アーカイブには、単一の 仮想デバイス に対応する複数のディレクトリが含まれています。
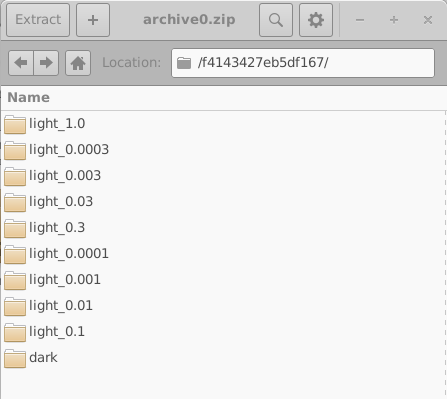
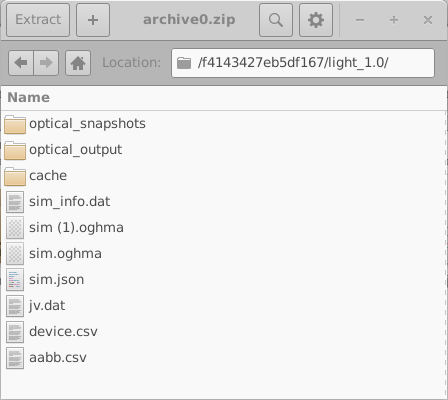
これらのディレクトリはランダムな 16 桁の 16 進識別子を用いて命名されています。 各ディレクトリには、1 つの仮想デバイスに対応する完全なシミュレーション集合が含まれます。 この例では、1 つの暗状態 JV シミュレーションと 9 つの照明下 JV シミュレーションです。 そのようなディレクトリの内容の 1 例を 18.10 の左側に示します。 個々のシミュレーションディレクトリを開くと (18.10、右)、 sim.json ファイルや、シミュレートされた電流–電圧特性を含む jv.dat ファイルを含む、完全な OghmaNano シミュレーションが現れます。 光学出力やキャッシュファイルのような追加データも存在する場合があります。
大規模な機械学習データセットを生成する際には、総ディスク使用量が急速に増大する可能性があるため、 不要な出力を最小化することを強く推奨します。 これは、シミュレーションが本質的に必要な出力データのみを生成するよう設定することで達成できます。 データセット生成はバッチ単位で行われ、シミュレーションは利用可能なすべての CPU コアにわたって並列実行され、 アーカイブ作成は単一コアで処理されます。
この説明用の例では 3 つのアーカイブのみが生成されます。 しかし、典型的な本番実行では、およそ 200 個のアーカイブを生成し、それぞれに約 200 個の仮想デバイスを含めることが一般的です。
上の例ではアーカイブは 3 つしかありませんが、通常のシミュレーション実行では最大 200 個のアーカイブがあり、それぞれに 200 個のシミュレーションが含まれます。
7. 結果を単一ファイルへまとめる
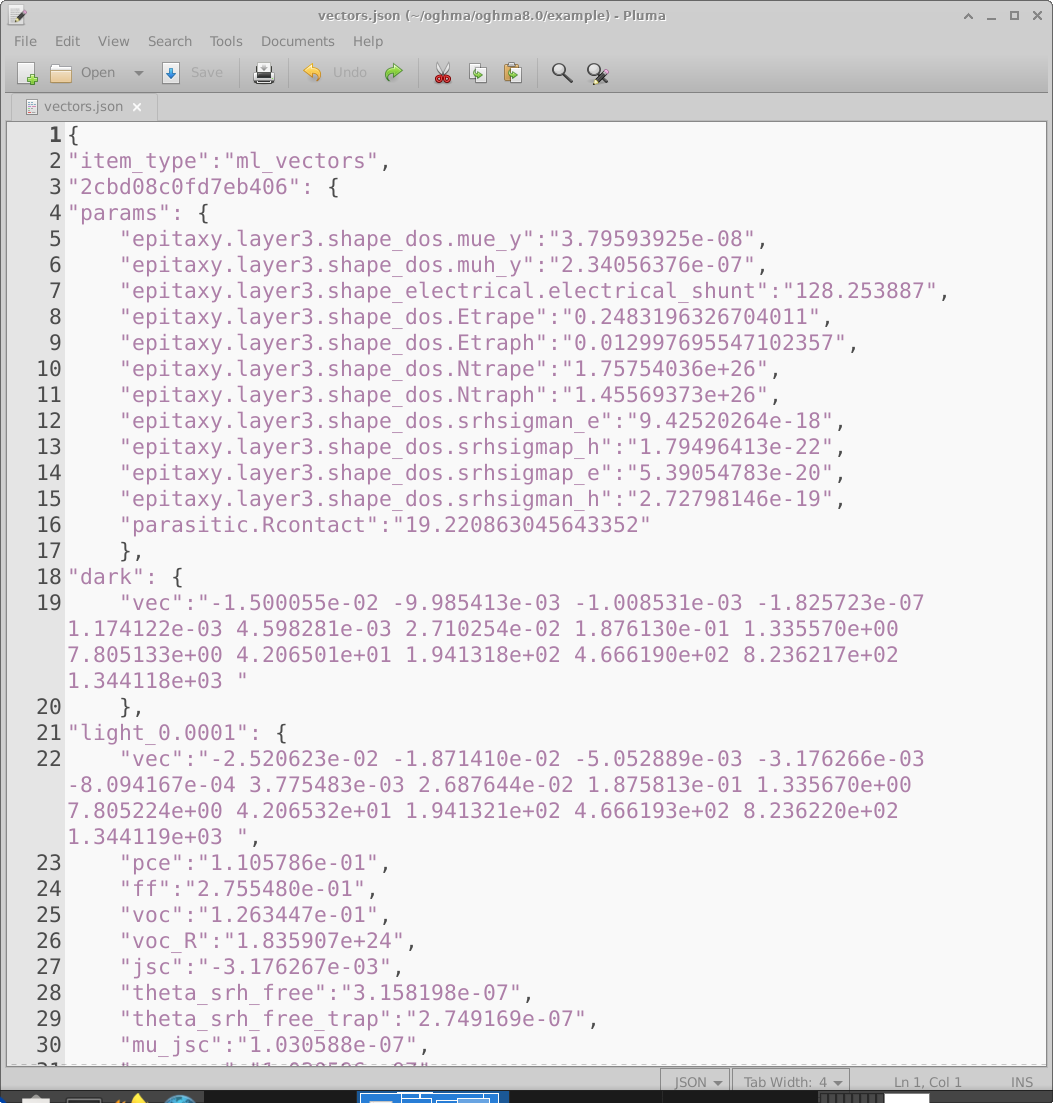
シミュレーションが完了したら、生の OghmaNano 出力を、機械学習モデルの学習に適した単一の vectors ファイルへ 変換する必要があります。メイン Machine learning ウィンドウの Build vectors アイコンをクリックすると (18.2)、 OghmaNano は各 仮想デバイス ディレクトリを開き、要求された出力を抽出し、 それらを単一の vectors.json ファイルへまとめます。このファイルの例を 18.11 に示します。
ベクトルファイルは、教師あり学習に必要なすべての情報を含む JSON 文書です。各
仮想デバイス は独立したエントリとして現れます。例えば、
2cbd08c0fd7eb406(3 行目)というラベルの付いたエントリには、params セクションの下に、その仮想デバイスのためにランダムに
選択された電気パラメータが含まれています。これに続いて、暗状態 JV ベクトル(19 行目)
および 0.0001 Suns における照明下 JV ベクトル(22 行目)のような、抽出された入力ベクトルが続きます。各ベクトルの数値単位は、
抽出元ファイルから直接継承されます。この例ではベクトルは jv.dat から取得されており、このファイルは
電圧の関数としての電流密度を \(A\,m^{-2}\) で格納しているため、ベクトル値も
\(A\,m^{-2}\) になります。入力ベクトルの後には、利便性のために PCE のような追加のスカラー出力も
保存されます。
このファイルには、生成されたすべての仮想デバイスについて 1 つずつエントリが存在します。いったん vectors.json が生成されれば、 それは任意の機械学習ワークフローの学習データセットとして使用できます。標準的な Python ライブラリを使って CSV に変換してから TensorFlow に取り込む方が扱いやすいと感じるユーザーもいます。
8. データセットから機械学習へ
前節まででは、OghmaNano を用いて JSON 形式の完全な機械学習データセットを生成する方法を説明しました。 この時点で、データ生成パイプラインは完了しています。各 仮想デバイス について、 このファイルにはランダムに選ばれたモデルパラメータと、それに対応するシミュレーション出力が入力ベクトルとして 含まれています。
次のステップは、このデータをお好みの機械学習フレームワークへ取り込むことです。
実際には、通常、vectors.json ファイルを読み込み、それを
CSV のような表形式へ変換し、その後に学習、検証、およびテストに使用します。
この変換は、標準的なスクリプトツール(例えば Python)を使って容易に実行できます。
いったん変換されれば、このデータは TensorFlow、PyTorch、または類似のライブラリのような機械学習フレームワークを用いて実装された ニューラルネットワークやその他の回帰モデルの学習に使用できます。 この時点以降、ネットワークアーキテクチャ、損失関数、および学習戦略の選択は アプリケーション固有であり、OghmaNano から独立しています。
このようにして、OghmaNano は物理的に整合した学習データを生成するための完全かつ自動化されたパイプラインを提供し、 その後の機械学習モデルの開発と最適化はすべて ユーザーの管理下に委ねられます。