Gerando conjuntos de dados para Machine Learning
Este capítulo descreve como gerar conjuntos de dados para machine learning usando o OghmaNano. Normalmente, esses conjuntos de dados são exportados e processados usando frameworks externos, como TensorFlow, para treinamento, inferência ou predição.
1. Introdução
Frequentemente é desejável extrair parâmetros físicos do dispositivo a partir de dados experimentais usando modelagem. Por exemplo, pode-se ter um conjunto de curvas JV e desejar determinar a mobilidade dos portadores de carga e a taxa de recombinação do dispositivo. Tradicionalmente, isso é obtido ajustando um modelo baseado em física, como o OghmaNano, aos dados (como descrito no tutorial de ajuste). A desvantagem dessa abordagem é que ajustar um único conjunto de dados pode consumir muito tempo, e a dificuldade aumenta substancialmente quando múltiplos conjuntos de dados precisam ser analisados. O processo de ajuste é complexo, tipicamente exigindo experiência significativa em simulação numérica e uma quantidade considerável de intervenção manual. Como resultado, o ajuste detalhado de dispositivos é realizado apenas por um subconjunto relativamente pequeno da comunidade.
Uma abordagem mais moderna é usar machine learning. Em vez de ajustar diretamente uma única curva JV, primeiro é construída uma simulação que representa a estrutura do dispositivo. Em vez de otimizar parâmetros elétricos individuais, muitos milhares de cópias desse dispositivo são geradas com valores de parâmetros escolhidos aleatoriamente. Cada uma dessas instâncias é chamada de dispositivo virtual. Um programa de simulação como o OghmaNano é então usado para gerar curvas JV para cada dispositivo virtual, produzindo um conjunto de dados composto por curvas JV pareadas com seus parâmetros elétricos correspondentes. Esses dados podem ser usados para treinar um modelo de machine learning a prever parâmetros elétricos diretamente a partir das características JV. Nesse contexto, o OghmaNano atua como uma transformação direta, mapeando parâmetros elétricos para dados experimentais simulados, enquanto o modelo de machine learning fornece a transformação inversa. Depois de treinado, o modelo pode ser aplicado para extrair parâmetros de materiais de dispositivos reais.
A principal vantagem dessa abordagem é que, uma vez treinado, o modelo de machine learning pode extrair parâmetros de materiais a partir de dados experimentais em segundos, sem exigir que o usuário seja um especialista em simulação numérica. No entanto, o sucesso desse método depende criticamente da geração de um conjunto de dados de treinamento grande e de alta qualidade. O processo de construção desses conjuntos de dados usando o OghmaNano é descrito nas páginas a seguir.
2. Abrindo o exemplo
O exemplo discutido nesta página pode ser acessado pelo botão New simulation na janela principal. Isso abre o navegador New simulation mostrado em ??.
Na lista de categorias de simulação disponíveis, clique duas vezes em Machine learning para exibir os exemplos de machine learning (??). Selecionar o PM6:Y6 ML example carrega uma simulação pré-configurada correspondente ao dispositivo e ao fluxo de trabalho discutidos neste capítulo.
Uma vez aberta, a simulação apresenta a mesma estrutura de dispositivo e configuração de automação usadas ao longo desta seção, e pode ser usada diretamente para gerar dados de treinamento para machine learning sem configuração adicional.
3. Definindo as simulações e os vetores de saída
Depois que a simulação de exemplo for aberta, será apresentada a janela principal de simulação mostrada na Figura ??. Essa janela mostra a estrutura completa do dispositivo usada ao longo deste capítulo. Na faixa de opções Automation, um ícone Machine learning fica visível, representado por um símbolo circular azul. Clicar nesse ícone abre a janela principal de controle de machine learning mostrada na Figura ??. A partir dessa janela, a geração de dados de treinamento para machine learning é configurada e executada.
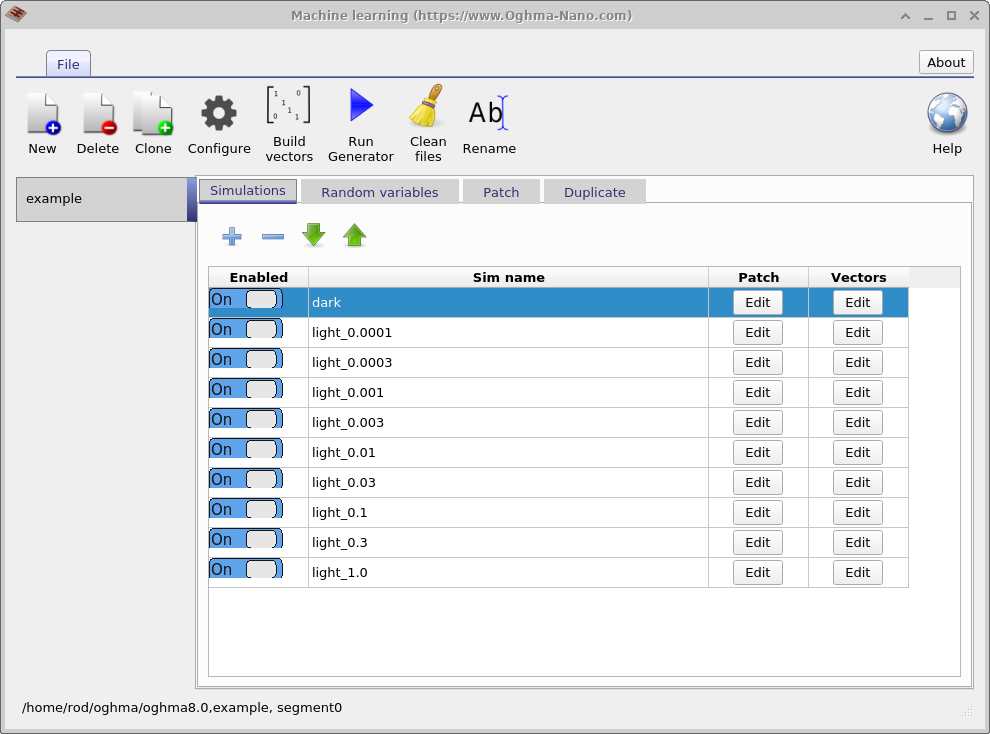
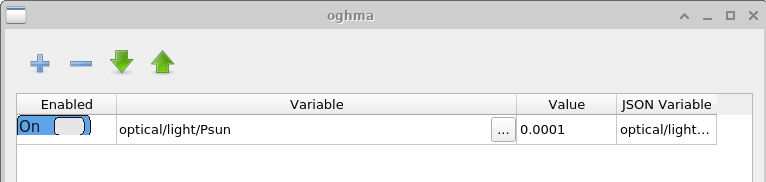
O propósito principal dessa janela é gerar grandes conjuntos de dados para treinamento de algoritmos de machine-learning. O conjunto de dados produzido neste exemplo é chamado de example. A primeira aba mostrada é a aba Simulations, que define o conjunto de simulações executadas para cada dispositivo virtual. Neste caso, são simuladas uma curva JV no escuro e nove curvas JV iluminadas, com intensidades de luz variando de 0.0001 Suns a 1.0 Suns. Simulações individuais podem ser habilitadas ou desabilitadas usando a chave Enabled. Se o botão Edit for clicado na coluna Patch para a entrada \(light\_0.0001\), a Patch window mostrada em ?? é aberta.
O objetivo da Patch window é modificar parâmetros dentro de uma simulação virtual. Neste exemplo, múltiplas curvas JV são geradas sob diferentes condições de iluminação usando a mesma estrutura base do dispositivo. Para conseguir isso, a intensidade da luz precisa ser ajustada independentemente para cada simulação. Abrir a patch window para \(light\_0.0001\) mostra que o parâmetro de simulação optical/light/Psun, que controla a intensidade de iluminação, está definido como \(0.0001\). Para a simulação dark, o mesmo parâmetro é definido como \(0.0\). Dessa forma, múltiplas condições experimentais podem ser simuladas de maneira consistente usando uma única simulação base.
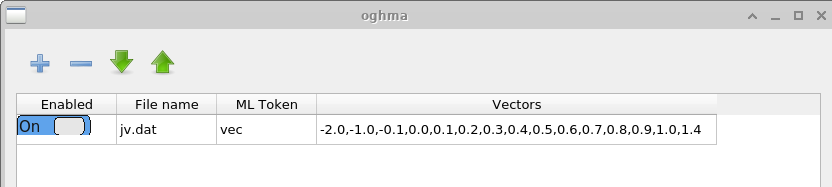
A janela Vectors define quais dados são extraídos das simulações concluídas para formar os vetores de entrada do machine learning. Neste exemplo, pontos de dados entre −2.0 V e 1.4 V são extraídos do arquivo \(jv.dat\), que contém as características simuladas de corrente–tensão. Para simulações no domínio do tempo, um usuário poderia em vez disso extrair dados de arquivos como \(time\_i.csv\) ou de qualquer outro arquivo de saída apropriado. O número de pontos usados para construir cada vetor de entrada é escolhido pelo usuário. Vetores mais longos aumentam o custo computacional do treinamento, mas podem capturar características mais detalhadas da curva JV.
4. Definindo as variáveis aleatórias
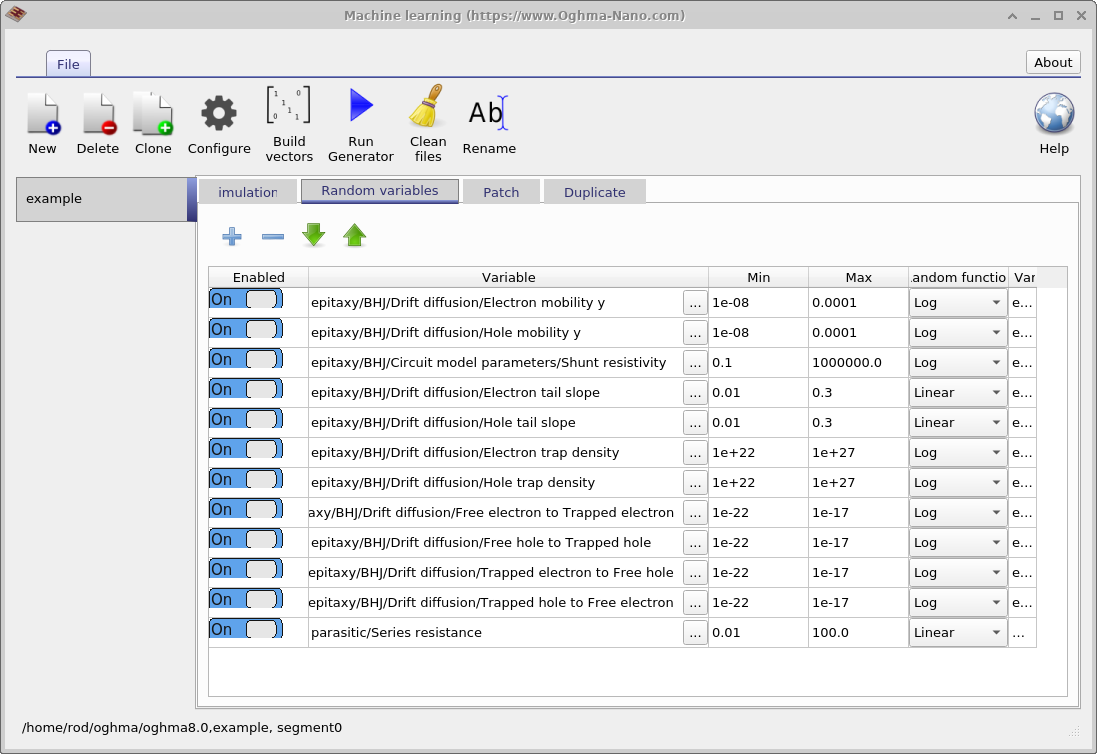
O próximo passo é definir quais parâmetros do modelo serão randomizados. Isso é feito usando a aba Random variables na janela principal de machine-learning. A tabela contém cinco colunas. A coluna Enabled determina se um parâmetro é incluído no processo de randomização. A coluna Variable especifica qual parâmetro de simulação é variado. As colunas Min e Max definem os limites inferior e superior do intervalo do parâmetro, e a coluna Random function especifica se os valores são extraídos de uma distribuição linear ou logarítmica.
Distribuições logarítmicas são recomendadas para parâmetros que abrangem várias ordens de magnitude, enquanto distribuições lineares são apropriadas para parâmetros que variam em um intervalo relativamente estreito. Usar uma distribuição logarítmica garante que os valores sejam amostrados uniformemente quando vistos em escala logarítmica, em vez de ficarem concentrados na extremidade superior do intervalo. Por exemplo, um parâmetro linear apropriado seria a energia de Urbach, que normalmente varia entre 30 e 150 meV. Em contraste, densidades de armadilhas são adequadas para amostragem logarítmica, pois podem variar de \(1 \times 10^{15}\,\mathrm{m^{-3}}\) a \(1 \times 10^{25}\,\mathrm{m^{-3}}\).
5. Definindo o número de simulações
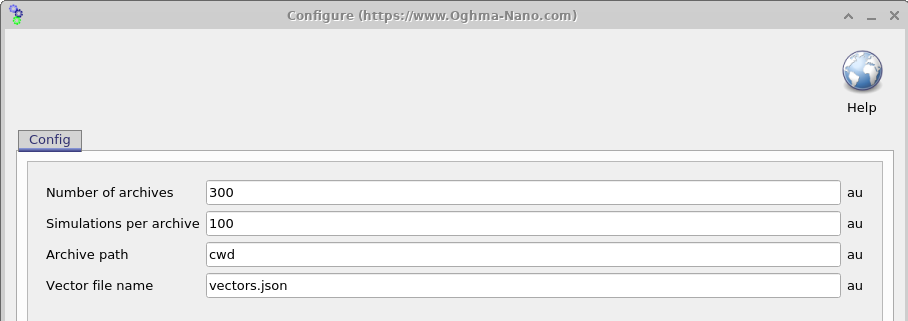
Uma vez que a simulação tenha sido configurada, o próximo passo é determinar quantos dispositivos virtuais com parâmetros randomizados devem ser gerados. Abrir a Settings window (veja 18.6) permite controlar isso usando dois parâmetros: Simulations per archive (\(N_{\mathrm{sim}}\)) e Number of archives (\(N_{\mathrm{arc}}\)). O número total de dispositivos virtuais gerados é dado por \(N_{\mathrm{sim}} \times N_{\mathrm{arc}}\).
Os resultados das simulações são gravados em arquivos ZIP chamados de archives, com cada archive contendo \(N_{\mathrm{sim}}\) dispositivos virtuais. No exemplo mostrado aqui, \(N_{\mathrm{sim}} \times N_{\mathrm{arc}} = 3000\) dispositivos virtuais são gerados e armazenados em 100 arquivos archive. É importante notar que, neste exemplo, cada dispositivo virtual consiste em uma simulação JV no escuro e nove simulações JV iluminadas. Como resultado, o número total de arquivos de saída pode crescer rapidamente.
Para gerenciar isso, a geração de dados é realizada em lotes. Um grupo de \(N_{\mathrm{sim}}\) simulações é gerado e executado pelo OghmaNano, depois gravado em um único archive, e esse processo é repetido até que \(N_{\mathrm{arc}}\) archives tenham sido produzidos. Essa abordagem limita a perda de dados ao archive que está sendo gerado no momento se o processo for interrompido, e também simplifica a transferência de arquivos e melhora a robustez contra corrupção. A execução das simulações é paralelizada em todos os núcleos de CPU disponíveis, enquanto a criação dos archives é realizada em um único núcleo.
6. Executando o gerador de conjunto de dados
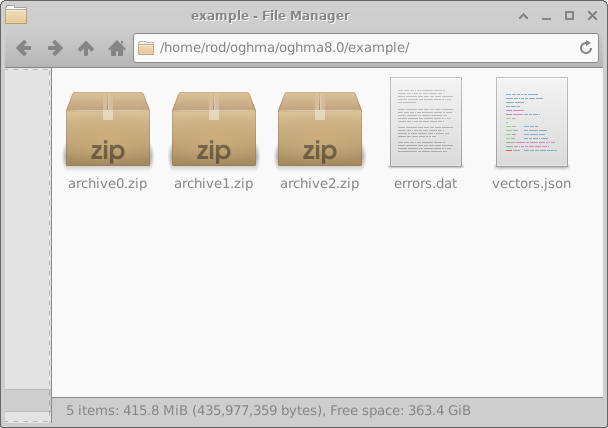
Uma vez concluída a configuração, pressionar o botão Run generator na janela principal de Machine learning (18.2) inicia o processo de geração do conjunto de dados. OghmaNano então começará a executar as simulações definidas para cada dispositivo virtual. Quando o processo terminar, um diretório chamado example aparecerá no diretório da simulação, como mostrado no lado esquerdo de 18.8. Para os propósitos deste exemplo, Simulations per archive foi definido como 10 e Number of archives foi definido como 3 para reduzir o tempo de execução.
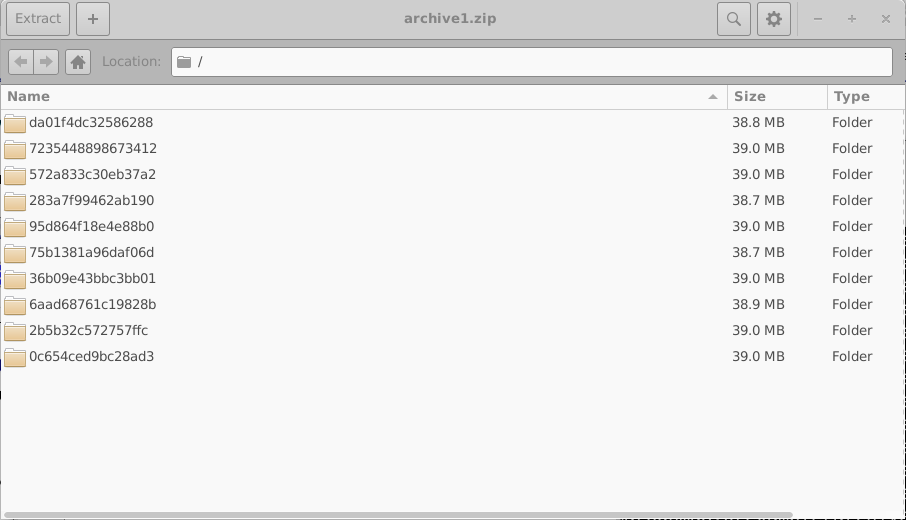
Quaisquer erros encontrados durante a simulação são gravados no arquivo errors.dat. Abrir archive0.zip revela a estrutura interna de um archive, mostrada no lado direito de 18.8. Cada archive contém uma coleção de diretórios, cada um correspondente a um único dispositivo virtual.
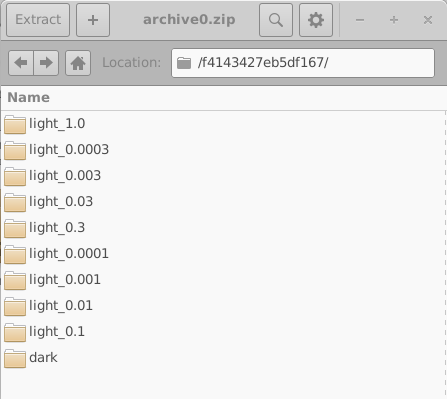
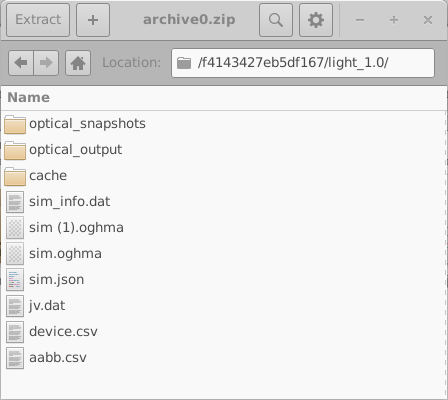
Esses diretórios são nomeados usando identificadores hexadecimais aleatórios de 16 dígitos. Cada diretório contém o conjunto completo de simulações para um dispositivo virtual; neste exemplo, uma simulação JV no escuro e nove simulações JV iluminadas. O conteúdo de um desses diretórios é mostrado no lado esquerdo de 18.10. Abrir um diretório de simulação individual (18.10, à direita) revela uma simulação completa do OghmaNano, incluindo o arquivo sim.json e o arquivo jv.dat contendo as características simuladas de corrente–tensão. Dados adicionais, como saídas ópticas e arquivos de cache, também podem estar presentes.
Ao gerar grandes conjuntos de dados para machine learning, é fortemente recomendado minimizar saídas desnecessárias, pois o uso total de disco pode crescer rapidamente. Isso pode ser obtido configurando a simulação para produzir apenas dados de saída essenciais. A geração do conjunto de dados é realizada em lotes, com as simulações executadas em paralelo em todos os núcleos de CPU disponíveis, enquanto a criação dos archives é tratada em um único núcleo.
Neste exemplo ilustrativo, apenas três archives são gerados. Em uma execução de produção típica, no entanto, é comum gerar da ordem de 200 archives, cada um contendo aproximadamente 200 dispositivos virtuais.
In the above example we only have three archives but in a normal simulation run one would have up to 200 archives each with 200 simulations in each.
7. Compilando os resultados em um único arquivo
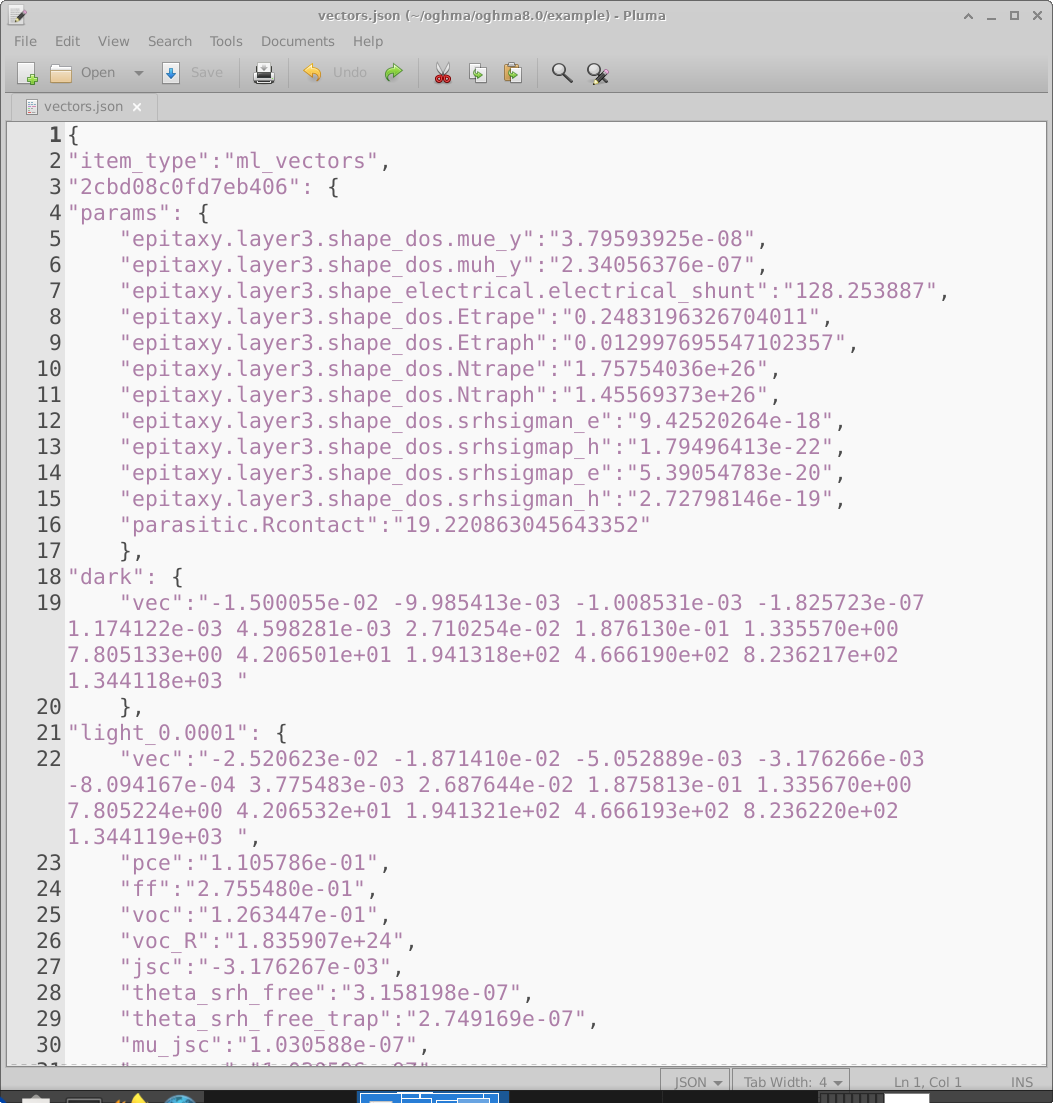
Uma vez concluídas as simulações, a saída bruta do OghmaNano deve ser convertida em um único arquivo de vectors adequado para treinar um modelo de machine-learning. Clicar no ícone Build vectors na janela principal de Machine learning (18.2) faz com que o OghmaNano abra cada diretório de dispositivo virtual, extraia as saídas solicitadas e as compile em um único arquivo vectors.json. Um exemplo desse arquivo é mostrado em 18.11.
O arquivo de vetores é um documento JSON contendo todas as informações necessárias para aprendizado supervisionado. Cada
dispositivo virtual aparece como uma entrada separada. Por exemplo, a entrada rotulada
2cbd08c0fd7eb406 (linha 3) contém, na seção params, os parâmetros elétricos aleatoriamente
selecionados para aquele dispositivo virtual. Em seguida, vêm os vetores de entrada extraídos, como o vetor JV no escuro (linha 19)
e o vetor JV iluminado a 0.0001 Suns (linha 22). As unidades numéricas em cada vetor são herdadas diretamente do
arquivo de origem do qual foram extraídas. Neste exemplo, os vetores são retirados de jv.dat, que armazena
densidade de corrente em \(A\,m^{-2}\) em função da tensão, de modo que os valores do vetor estão em
\(A\,m^{-2}\). Após os vetores de entrada, saídas escalares adicionais (por exemplo PCE) são
armazenadas por conveniência.
Haverá uma entrada nesse arquivo para cada dispositivo virtual gerado. Depois que vectors.json tiver sido produzido, ele poderá ser usado como conjunto de dados de treinamento para o fluxo de trabalho de machine-learning de sua escolha. Alguns usuários acham mais fácil importar os dados para o TensorFlow depois de convertê-los para CSV; isso pode ser feito com bibliotecas padrão de Python.
8. Do conjunto de dados ao machine learning
As seções anteriores descrevem como o OghmaNano é usado para gerar um conjunto completo de dados para machine-learning em formato JSON. Neste ponto, o pipeline de geração de dados está concluído: para cada dispositivo virtual, o arquivo contém os parâmetros do modelo escolhidos aleatoriamente juntamente com as saídas de simulação correspondentes codificadas como vetores de entrada.
O próximo passo é importar esses dados para um framework de machine-learning de sua escolha.
Na prática, isso normalmente envolve ler o arquivo vectors.json e convertê-lo para um
formato tabular como CSV, que então pode ser usado para treinamento, validação e teste.
Essa conversão pode ser feita de forma direta usando ferramentas padrão de scripting (por exemplo, Python).
Uma vez convertidos, os dados podem ser usados para treinar uma rede neural ou outro modelo de regressão implementado usando um framework de machine-learning como TensorFlow, PyTorch ou biblioteca similar. A partir desse ponto, a escolha da arquitetura da rede, da função de perda e da estratégia de treinamento é específica da aplicação e independente do OghmaNano.
Dessa forma, o OghmaNano fornece um pipeline completo e automatizado para gerar dados de treinamento fisicamente consistentes, deixando o desenvolvimento e a otimização subsequentes do modelo de machine-learning inteiramente sob o controle do usuário.