Generación de conjuntos de datos de aprendizaje automático
Este capítulo describe cómo generar conjuntos de datos de aprendizaje automático usando OghmaNano. Típicamente, estos conjuntos de datos se exportan y procesan usando marcos externos como TensorFlow para entrenamiento, inferencia o predicción.
1. Introducción
A menudo es deseable extraer parámetros físicos del dispositivo a partir de datos experimentales usando modelado. Por ejemplo, se puede tener un conjunto de curvas JV y desear determinar la movilidad de portadores de carga y la tasa de recombinación del dispositivo. Tradicionalmente, esto se consigue ajustando un modelo basado en física, como OghmaNano, a los datos (como se describe en el tutorial de ajuste). El inconveniente de este enfoque es que ajustar un único conjunto de datos puede llevar mucho tiempo, y la dificultad aumenta sustancialmente cuando deben analizarse múltiples conjuntos de datos. El proceso de ajuste es complejo y normalmente requiere una experiencia significativa en simulación numérica y una cantidad considerable de intervención manual. Como resultado, el ajuste detallado de dispositivos solo es realizado por un subconjunto relativamente pequeño de la comunidad.
Un enfoque más moderno es usar aprendizaje automático. En lugar de ajustar directamente una única curva JV, primero se construye una simulación que representa la estructura del dispositivo. En vez de optimizar parámetros eléctricos individuales, se generan muchos miles de copias de este dispositivo con valores de parámetros seleccionados aleatoriamente. Cada una de estas instancias se denomina dispositivo virtual. A continuación, un programa de simulación como OghmaNano se usa para generar curvas JV para cada dispositivo virtual, produciendo un conjunto de datos formado por curvas JV emparejadas con sus parámetros eléctricos correspondientes. Estos datos pueden utilizarse para entrenar un modelo de aprendizaje automático que prediga directamente los parámetros eléctricos a partir de las características JV. En este marco, OghmaNano actúa como una transformada directa, mapeando parámetros eléctricos a datos experimentales simulados, mientras que el modelo de aprendizaje automático proporciona la transformada inversa. Una vez entrenado, el modelo puede aplicarse para extraer parámetros de material de dispositivos reales.
La ventaja clave de este enfoque es que, una vez entrenado, el modelo de aprendizaje automático puede extraer parámetros de material de datos experimentales en cuestión de segundos, sin requerir que el usuario sea un experto en simulación numérica. Sin embargo, el éxito de este método depende de forma crítica de la generación de un conjunto de datos de entrenamiento grande y de alta calidad. El proceso de construcción de tales conjuntos de datos usando OghmaNano se describe en las páginas siguientes.
2. Apertura del ejemplo
Se puede acceder al ejemplo tratado en esta página mediante el botón New simulation en la ventana principal. Esto abre el explorador New simulation mostrado en ??.
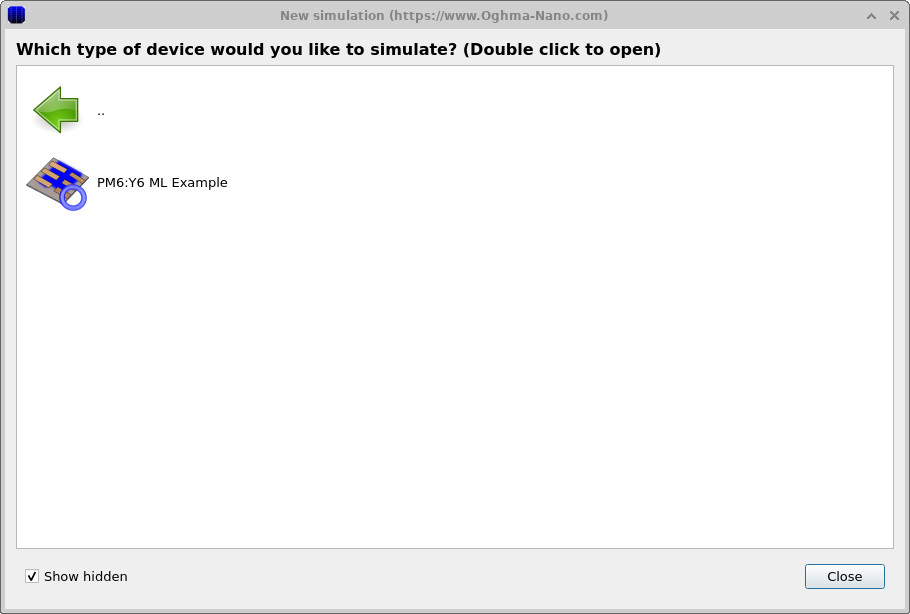
En la lista de categorías de simulación disponibles, haga doble clic en Machine learning para mostrar los ejemplos de aprendizaje automático (??). Seleccionar el PM6:Y6 ML example carga una simulación preconfigurada correspondiente al dispositivo y al flujo de trabajo tratados en este capítulo.
Una vez abierta, la simulación presenta la misma estructura de dispositivo y configuración de automatización usada a lo largo de esta sección, y puede emplearse directamente para generar datos de entrenamiento de aprendizaje automático sin necesidad de configuración adicional.
3. Definición de las simulaciones y los vectores de salida
Una vez abierta la simulación de ejemplo, se le presentará la ventana principal de simulación mostrada en la Figura ??. Esta ventana muestra la estructura del dispositivo completamente configurada usada en este capítulo. En la cinta Automation, es visible un icono de Machine learning, representado por un símbolo circular azul. Hacer clic en este icono abre la ventana principal de control de aprendizaje automático mostrada en la Figura ??. Desde esta ventana, se configura y ejecuta la generación de datos de entrenamiento para aprendizaje automático.
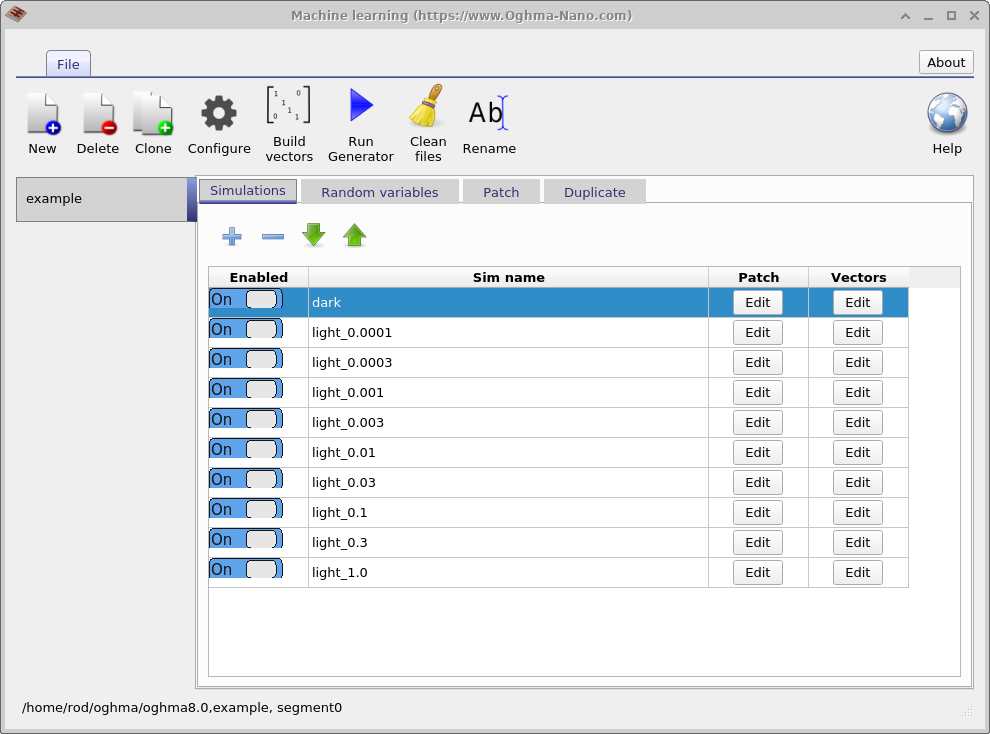
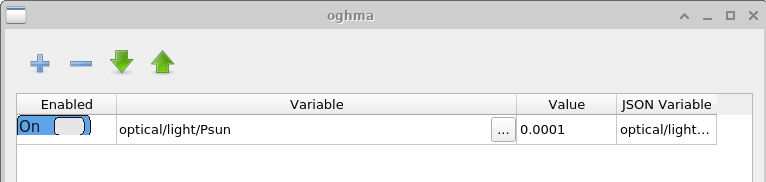
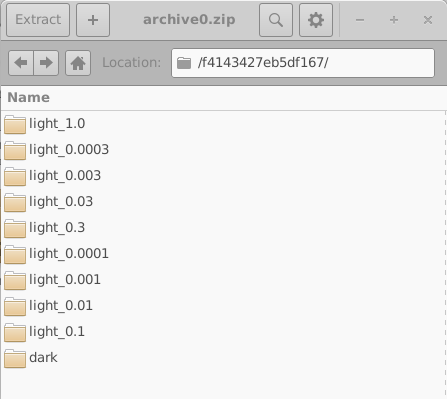
El propósito principal de esta ventana es generar grandes conjuntos de datos para entrenar algoritmos de aprendizaje automático. El conjunto de datos producido en este ejemplo se llama example. La primera pestaña mostrada es la pestaña Simulations, que define el conjunto de simulaciones realizadas para cada dispositivo virtual. En este caso, se simulan una curva JV en oscuridad y nueve curvas JV iluminadas, con intensidades de luz que van desde 0.0001 Suns hasta 1.0 Suns. Las simulaciones individuales pueden habilitarse o deshabilitarse usando el conmutador Enabled. Si se hace clic en el botón Edit de la columna Patch para la entrada \(light\_0.0001\), se abre la ventana Patch mostrada en ??.
El propósito de la ventana Patch es modificar parámetros dentro de una simulación virtual. En este ejemplo, se generan múltiples curvas JV bajo diferentes condiciones de iluminación usando la misma estructura base del dispositivo. Para conseguirlo, la intensidad de luz debe ajustarse independientemente para cada simulación. Abrir la ventana patch para \(light\_0.0001\) muestra que el parámetro de simulación optical/light/Psun, que controla la intensidad de iluminación, se establece en \(0.0001\). Para la simulación dark, el mismo parámetro se establece en \(0.0\). De este modo, pueden simularse múltiples condiciones experimentales de manera consistente usando una única simulación base.
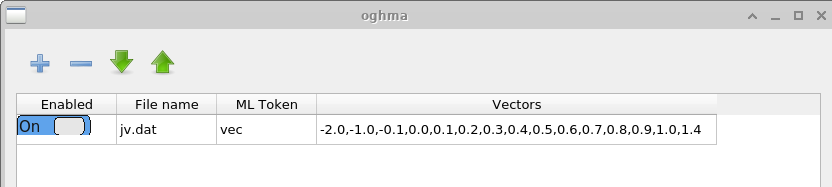
La ventana Vectors define qué datos se extraen de las simulaciones completadas para formar los vectores de entrada del aprendizaje automático. En este ejemplo, se extraen puntos de datos entre −2.0 V y 1.4 V del archivo \(jv.dat\), que contiene las características simuladas de corriente–voltaje. Para simulaciones en dominio temporal, un usuario podría extraer datos de archivos como \(time\_i.csv\) o cualquier otro archivo de salida apropiado. El número de puntos usados para construir cada vector de entrada es elegido por el usuario. Vectores más largos aumentan el coste computacional del entrenamiento, pero pueden capturar características más detalladas de la curva JV.
4. Definición de las variables aleatorias
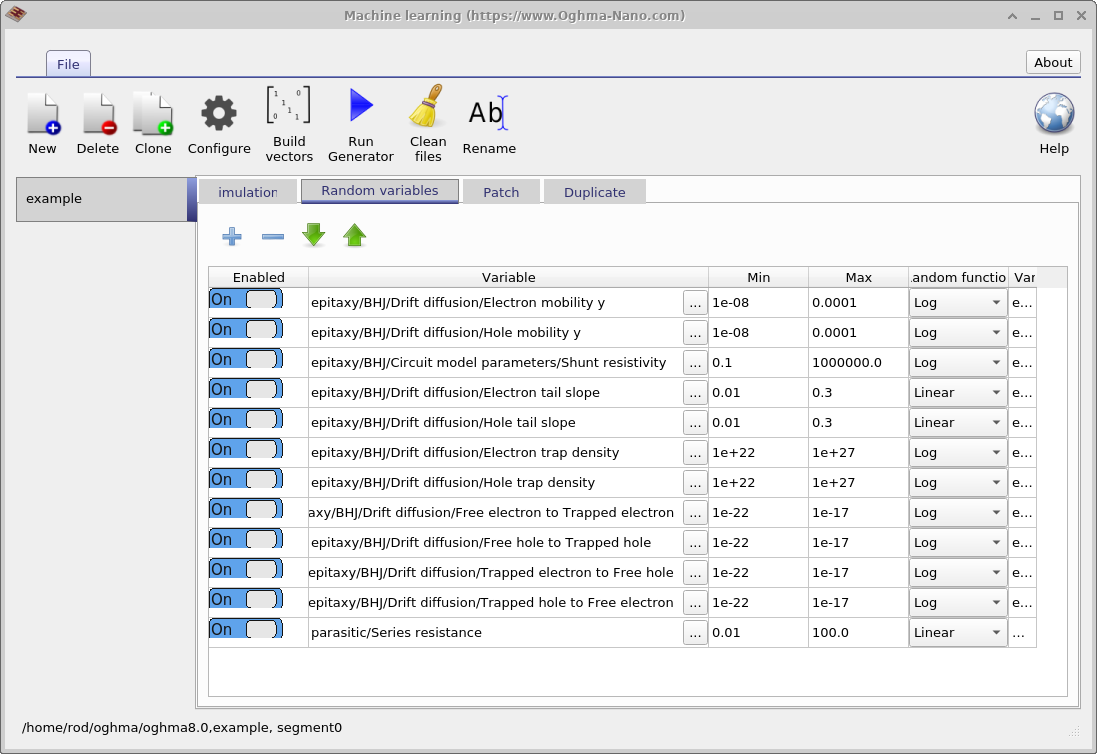
El siguiente paso es definir qué parámetros del modelo deben aleatorizarse. Esto se hace usando la pestaña Random variables en la ventana principal de aprendizaje automático. La tabla contiene cinco columnas. La columna Enabled determina si un parámetro se incluye en el proceso de aleatorización. La columna Variable especifica qué parámetro de simulación se varía. Las columnas Min y Max definen los límites inferior y superior del rango del parámetro, y la columna Random function especifica si los valores se extraen de una distribución lineal o logarítmica.
Se recomiendan distribuciones logarítmicas para parámetros que abarcan múltiples órdenes de magnitud, mientras que las distribuciones lineales son apropiadas para parámetros que varían en un rango relativamente estrecho. Usar una distribución logarítmica garantiza que los valores se muestreen uniformemente cuando se observan en una escala logarítmica, en lugar de agruparse hacia el extremo superior del rango. Por ejemplo, un parámetro lineal apropiado sería la energía de Urbach, que suele variar entre 30 y 150 meV. En cambio, las densidades de trampas se adaptan bien al muestreo logarítmico, ya que pueden variar desde \(1 \times 10^{15}\,\mathrm{m^{-3}}\) hasta \(1 \times 10^{25}\,\mathrm{m^{-3}}\).
5. Definición del número de simulaciones
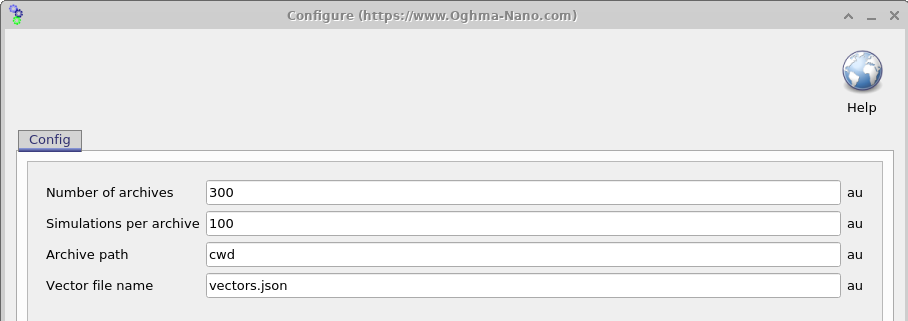
Una vez configurada la simulación, el siguiente paso es determinar cuántos dispositivos virtuales con parámetros aleatorizados deben generarse. Al abrir la Settings window (véase 18.6) esto puede controlarse usando dos parámetros: Simulations per archive (\(N_{\mathrm{sim}}\)) y Number of archives (\(N_{\mathrm{arc}}\)). El número total de dispositivos virtuales generados viene dado por \(N_{\mathrm{sim}} \times N_{\mathrm{arc}}\).
Los resultados de simulación se escriben en archivos ZIP denominados archives, y cada archivo contiene \(N_{\mathrm{sim}}\) dispositivos virtuales. En el ejemplo mostrado aquí, \(N_{\mathrm{sim}} \times N_{\mathrm{arc}} = 3000\) dispositivos virtuales se generan y almacenan en 100 archivos comprimidos. Es importante señalar que, en este ejemplo, cada dispositivo virtual consiste en una simulación JV en oscuridad y nueve simulaciones JV iluminadas. Como resultado, el número total de archivos de salida puede crecer rápidamente.
Para gestionar esto, la generación de datos se realiza por lotes. Se genera y ejecuta un grupo de \(N_{\mathrm{sim}}\) simulaciones con OghmaNano, luego se escribe en un único archivo comprimido, y este proceso se repite hasta que se hayan producido \(N_{\mathrm{arc}}\) archivos comprimidos. Este enfoque limita la pérdida de datos al archivo que se está generando en ese momento si el proceso se interrumpe, y además simplifica la transferencia de archivos y mejora la robustez frente a la corrupción. La ejecución de simulaciones se paraleliza a través de todos los núcleos de CPU disponibles, mientras que la creación del archivo comprimido se realiza en un único núcleo.
6. Ejecución del generador del conjunto de datos
Una vez completada la configuración, al pulsar el botón Run generator en la ventana principal de Machine learning (18.2) se inicia el proceso de generación del conjunto de datos. OghmaNano comenzará entonces a ejecutar las simulaciones definidas para cada dispositivo virtual. Cuando el proceso haya terminado, aparecerá un directorio denominado example en el directorio de simulación, como se muestra en el lado izquierdo de 18.8. Para los fines de este ejemplo, Simulations per archive se estableció en 10 y Number of archives se estableció en 3 para reducir el tiempo de ejecución.
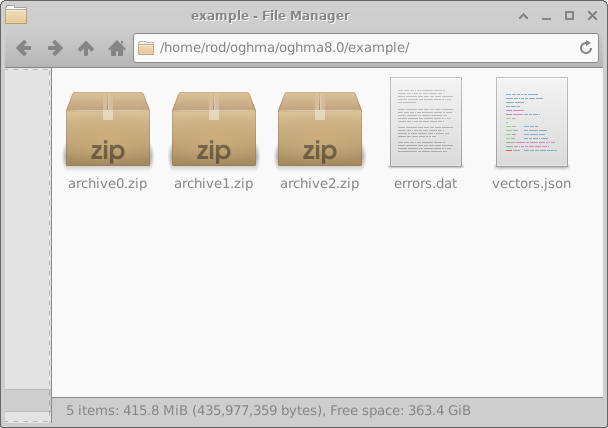
Cualquier error encontrado durante la simulación se escribe en el archivo errors.dat. Al abrir archive0.zip se revela la estructura interna de un archivo comprimido, mostrada en el lado derecho de 18.8. Cada archivo comprimido contiene una colección de directorios, cada uno correspondiente a un solo dispositivo virtual.
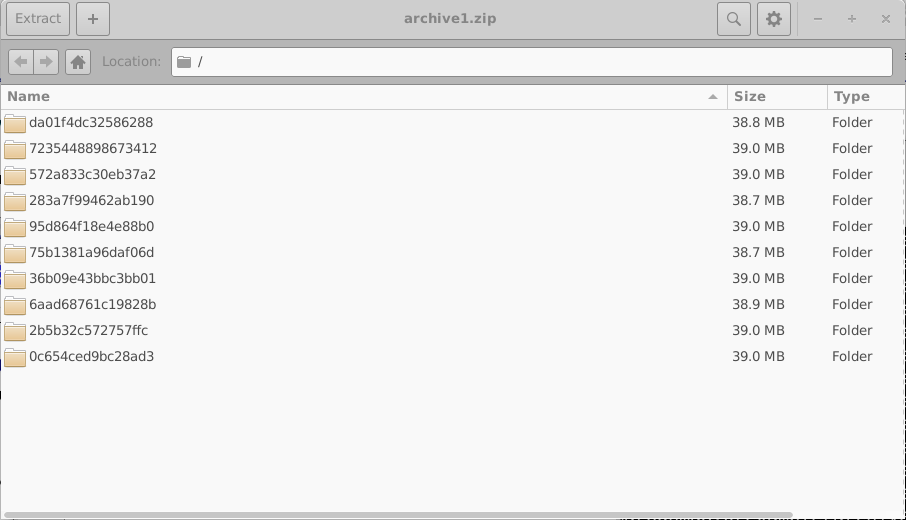
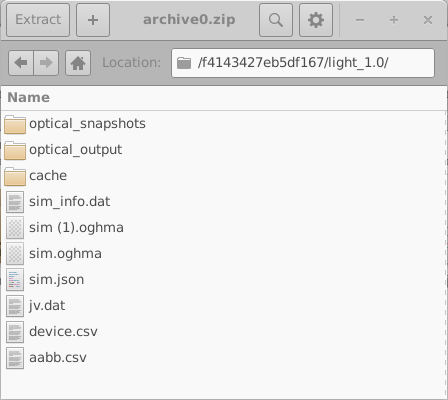
Estos directorios se nombran usando identificadores hexadecimales aleatorios de 16 dígitos. Cada directorio contiene el conjunto completo de simulaciones para un dispositivo virtual; en este ejemplo, una simulación JV en oscuridad y nueve simulaciones JV iluminadas. El contenido de uno de estos directorios se muestra en el lado izquierdo de 18.10. Abrir un directorio de simulación individual (18.10, derecha) revela una simulación completa de OghmaNano, incluyendo el archivo sim.json y el archivo jv.dat que contiene las características simuladas de corriente–voltaje. También pueden estar presentes datos adicionales, como salidas ópticas y archivos de caché.
Al generar grandes conjuntos de datos de aprendizaje automático, se recomienda encarecidamente minimizar la salida innecesaria, ya que el uso total de disco puede crecer rápidamente. Esto puede lograrse configurando la simulación para producir únicamente los datos de salida esenciales. La generación del conjunto de datos se realiza por lotes, con simulaciones ejecutadas en paralelo en todos los núcleos de CPU disponibles, mientras que la creación del archivo comprimido se maneja en un único núcleo.
En este ejemplo ilustrativo, solo se generan tres archivos comprimidos. En una ejecución de producción típica, sin embargo, es común generar del orden de 200 archivos comprimidos, cada uno conteniendo aproximadamente 200 dispositivos virtuales.
En el ejemplo anterior solo tenemos tres archivos comprimidos, pero en una ejecución de simulación normal se tendrían hasta 200 archivos comprimidos con 200 simulaciones en cada uno.
7. Compilación de los resultados en un único archivo
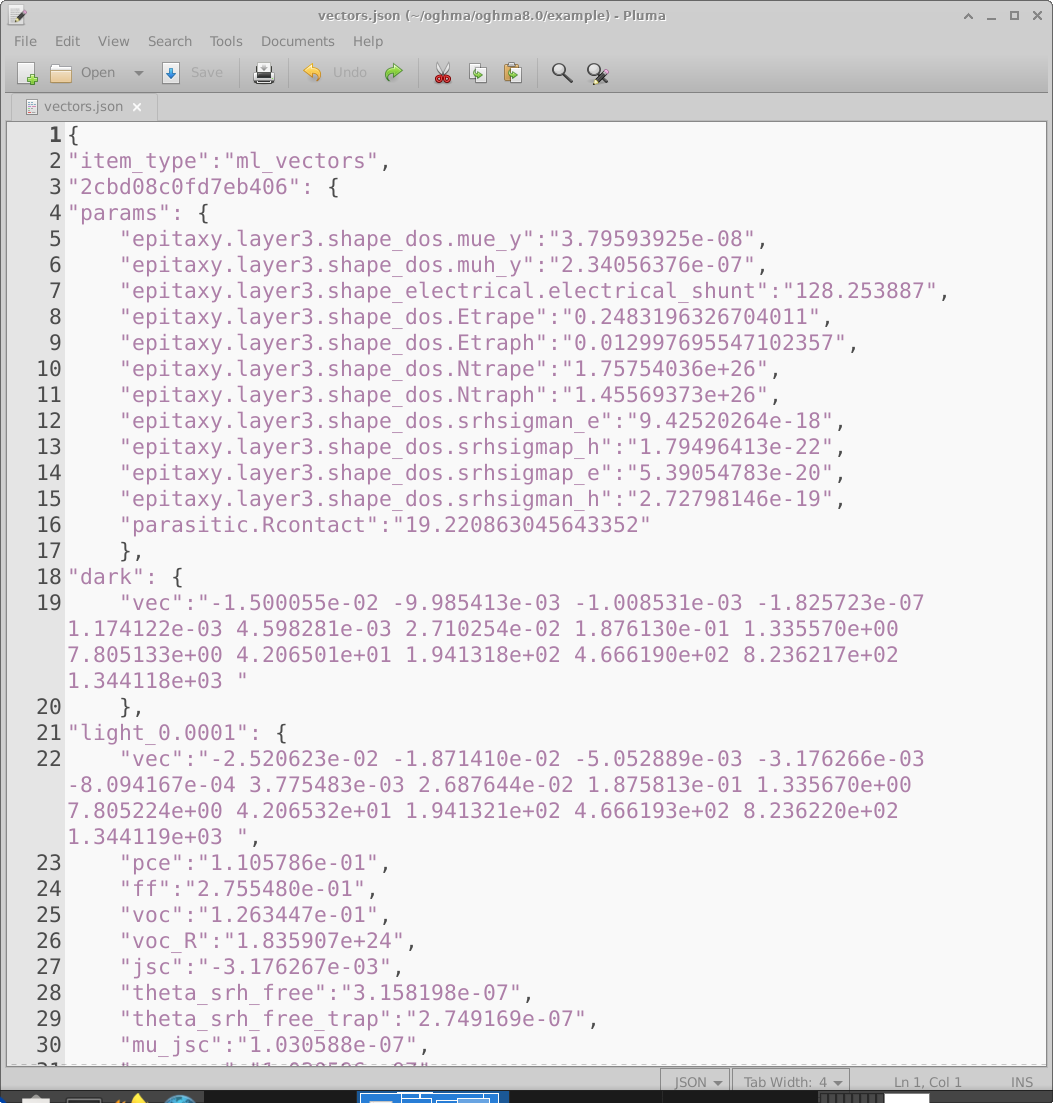
Una vez completadas las simulaciones, la salida bruta de OghmaNano debe convertirse en un único archivo de vectors adecuado para entrenar un modelo de aprendizaje automático. Haciendo clic en el icono Build vectors en la ventana principal de Machine learning (18.2) hace que OghmaNano abra cada directorio de dispositivo virtual, extraiga las salidas solicitadas y las compile en un único archivo vectors.json. Se muestra un ejemplo de este archivo en 18.11.
El archivo de vectores es un documento JSON que contiene toda la información requerida para aprendizaje supervisado. Cada
dispositivo virtual aparece como una entrada separada. Por ejemplo, la entrada etiquetada
2cbd08c0fd7eb406 (línea 3) contiene, en la sección params, los parámetros eléctricos aleatorios
seleccionados para ese dispositivo virtual. A continuación aparecen los vectores de entrada extraídos, como el vector JV en oscuridad (línea 19)
y el vector JV iluminado a 0.0001 Suns (línea 22). Las unidades numéricas de cada vector se heredan directamente del
archivo fuente del que se extraen. En este ejemplo los vectores se toman de jv.dat, que almacena
densidad de corriente en \(A\,m^{-2}\) en función del voltaje, por lo que los valores del vector están en
\(A\,m^{-2}\). Tras los vectores de entrada, se almacenan salidas escalares adicionales (por ejemplo PCE)
por comodidad.
Habrá una entrada en este archivo por cada dispositivo virtual generado. Una vez que se haya producido vectors.json, puede usarse como el conjunto de datos de entrenamiento para el flujo de trabajo de aprendizaje automático que prefiera. A algunos usuarios les resulta más fácil importar los datos en TensorFlow después de convertirlos a CSV; esto puede hacerse usando bibliotecas estándar de Python.
8. Del conjunto de datos al aprendizaje automático
Las secciones anteriores describen cómo se usa OghmaNano para generar un conjunto completo de datos de aprendizaje automático en formato JSON. En este punto, el flujo de generación de datos ha terminado: para cada dispositivo virtual, el archivo contiene los parámetros del modelo elegidos aleatoriamente junto con las salidas de simulación correspondientes codificadas como vectores de entrada.
El siguiente paso es importar estos datos en el marco de aprendizaje automático de su elección.
En la práctica, esto normalmente implica leer el archivo vectors.json y convertirlo a un
formato tabular como CSV, que luego puede utilizarse para entrenamiento, validación y prueba.
Esta conversión puede realizarse de forma sencilla usando herramientas estándar de scripting (por ejemplo, Python).
Una vez convertidos, los datos pueden usarse para entrenar una red neuronal u otro modelo de regresión implementado usando un marco de aprendizaje automático como TensorFlow, PyTorch o una biblioteca similar. A partir de este punto, la elección de la arquitectura de red, la función de pérdida y la estrategia de entrenamiento es específica de la aplicación e independiente de OghmaNano.
De este modo, OghmaNano proporciona una tubería completa y automatizada para generar datos de entrenamiento físicamente consistentes, dejando el posterior desarrollo y optimización del modelo de aprendizaje automático enteramente bajo el control del usuario.